3 The document level
3.1 Transcription of a document
- document
- Writing Surface (page, double page, folium, etc.)
- zone
- Text, lines or tables
- zone
- Writing Surface (page, double page, folium, etc.)
- a TEI Header, containing metadata
- a TEI facsimile element, containing and describing visual representations of a document
- a <ge:document> element, containing a genetic transcription of a document
- a TEI text element, containing an encoded version of the text constructed from the document.
- document contains a document-centric transcription of a primary source, providing topographical information as well as transcription
-
surface
defines a written surface in terms of a rectangular
coordinate space, optionally grouping one or more graphic representations of
that space, and rectangular zones of interest
within it.
type characterizes the element in some sense, using any convenient classification scheme or typology. -
zone
defines a rectangular area contained within a surface
element.
rotate indicates the amount by which this zone has been rotated clockwise, with respect to the normal orientation of the parent surface element as implied by the dimensions given in the msDesc section or by the coordinates of the surface itself. The orientation is expressed in arc degrees. -
line
contains the transcription of a topographic line in the source
document
type characterizes the element in some sense, using any convenient classification scheme or typology. - table contains text displayed in tabular form, in rows and columns.
Like a facsimile, a <ge:document> contains information about the written surfaces constituting a document. Because of this similarity, we would like to use the same elements (surface and zone) as proposed in the existing TEI scheme, although these place limits on what can be described. Specifically, the zone element as currently defined can represent only a rectangular area; it also lacks any way of stating the baseline applicable to any writing contained within it
The size of the writing surface is defined by a set of cartesian coordinates measured from the top left corner. The co-ordinates of all zones identified within the writing surface are given in terms of the same co-ordinates, as further discussed in the TEI proposals for facsimile. It will often be the case that explicit dimensions for a manuscript page (expressed in mm for example) are also supplied in a msDesc element in the TEI Header, but this is not a requirement; in particular there is no assumption that the co-ordinate system defined by a surface maps to any particular external dimensions, nor that the co-ordinate systems of different documents necessarily correspond.
A surface element may contain any number of zone, graphic, <ge:line> or tableelements. The graphic element is used to point to any graphic (non textual) component forming part of the page, in the usual TEI manner. The zone element is used to delimit any contiguous section of writing which the encoder wishes to identify for some purpose.
Zones can be nested and grouped, and can also overlap. Their positioning with respect to the surface element is defined by coordinate values taken from the same co-ordinate system as the surface itself, measured from the top left corner. The element carries a rotate attribute which describes (in degrees) the orientation of the surface with respect to the content (writing, images) in that zone, with respect to its normal orientation. Note that the mechanism aims to describes the process by which the content of a specific zone has been supplied (i.e. the author has physically rotated the writing surface) rather than the orientation of the writing.
Zones are arbitrarily defined by the encoder according to the layout of the writing surface and can make use of a standardised vocabulary (e.g. the top margin).
To overcome the inherent limitations of the existing zone and surface elements, we need to extend their capability to include the definition of arbitrary polygons, using an attribute such as svg:points, from the Standard Vector Graphics (SVG) XML namespace. This would also provide a way of defining a baseline for the writing. This work is not yet fully elaborated.
The attribute stage is used to indicate the stage in a writing campaign to which this zone has been assigned by the encoder, as further discussed in 6.1 Stages/ Revision campaigns below.
Within a zone, individual lines of writing are usually, but not necessarily, distinguished using the <ge:line>. Zones can also include table elements, as lines and tables represent the principal ways of organising texts on a surface. In the case of an interlineated text, interlinear writing can be treated as a line on its own (perhaps characterised by a type attribute) or as textual addition, encoded with an add (see below 3.2 Textual Alterations).

<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone
ulx="10"
uly="43"
lrx="185"
lry="84"
rotate="0">
<zone>
<ge:line rend="right"> 1 April 2009 </ge:line>
</zone>
<ge:line>Fed Birds in the park today.</ge:line>
<ge:line>Might write an article about </ge:line>
<ge:line>the Thick-billed Warbler. </ge:line>
</zone>
<zone
ulx="9"
uly="20"
lrx="70"
lry="60"
rotate="90">
<ge:line>Samaria is a Greek </ge:line>
<ge:line>brand of water that</ge:line>
<ge:line>comes from the natural</ge:line>
<ge:line>springs of Stilos, in </ge:line>
<ge:line>Crete </ge:line>
</zone>
</surface></ge:document>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone
ulx="10"
uly="43"
lrx="185"
lry="84"
rotate="0">
<zone>1 April 2009 </zone>
<lb/>Fed Birds in the park today.<lb/> Might write an article about
<lb/> the Thick-billed Warbler. </zone>
<zone
ulx="9"
uly="20"
lrx="70"
lry="60"
rotate="90">
<lb/>Samaria is a Greek <lb/> brand of water that <lb/> comes from the
natural <lb/> springs of Stilos, in <lb/> Crete </zone>
</surface></ge:document>
<dateline>
<date value="2009-04-01"> 1 April 2009 </date>
</dateline>
<p>
<lb/>Fed Birds in the park today.<lb/> Might write an article about <lb/>
the Thick-billed Warbler. </p>
</div>
<div type="note" rend="rotated">
<p>
<lb/>Samaria is a Greek <lb/> brand of water that <lb/> comes from the
natural <lb/> springs of Stilos, in <lb/> Crete</p>
</div>
Is it possible to combine both perspectives (documentary and textual views) within a single encoding? In general a document-based transcription, which is done page-by-page and possibly line-by-line, is almost certain to overlap with some part of a the text-based structure. The cleanest solution may be to encode both structures separately, providing both a <ge:document> and a distinct text solution, perhaps using some form of external pointing to link the two, and minimizing redundancy of encoding by using XInclude. This option is further discussed below and also in the TEI Guidelines.
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone
stage="#stage1"
seq="0"
ulx="10"
uly="43"
lrx="185"
lry="84">
<zone>
<milestone unit="date" spanTo="#endDate"/>1 April 2009 <anchor xml:id="endDate"/>
</zone>
<milestone unit="p" spanTo="#p2"/>
<ge:line>Fed Birds in the park today.</ge:line>
<ge:line> Might write an article about </ge:line>
<ge:line>the Thick-billed Warbler.</ge:line>
</zone>
<zone
stage="#stage2"
ulx="9"
uly="20"
lrx="70"
lry="60"
rotate="90">
<milestone unit="p" xml:id="p2" spanTo="#end"/>
<ge:line>Samaria is a Greek</ge:line>
<ge:line>brand of water that</ge:line>
<ge:line>comes from the natural</ge:line>
<ge:line>springs of Stilos, in</ge:line>
<ge:line>Crete</ge:line>
<anchor xml:id="end"/>
</zone>
</surface>
- model.pPart.transcriptional groups phrase-level elements used for editorial transcription of pre-existing source materials.
- model.pPart.editorial groups phrase-level elements for simple editorial interventions that may be useful both in transcribing and in authoring.
- model.hiLike groups phrase-level elements which are typographically distinct but to which no specific function can be attributed.
- model.gLike groups elements used to represent individual non-Unicode characters or glyphs.
- model.global groups elements which may appear at any point within a TEI text.

-
patch
contains a part of a written surface which was originally physically
distinct but became attached to it at the time that one or more written zones
were created.
binder Describe the method by which a patch is or was connected to the main surface type characterizes the element in some sense, using any convenient classification scheme or typology. height height of the patch in mm width width of the patch in mm
<zone>
<ge:line>Poem</ge:line>
<ge:line>As in Visions of — at</ge:line>
<ge:line>night —</ge:line>
<ge:line>All sorts of fancies running through</ge:line>
<ge:line>the head</ge:line>
</zone>
<ge:patch
type="newsprint"
binder="glue"
height="40"
width="90"> Spring has
just set in here, and the weather.... a steamer <zone>
<ge:metaMark function="sequence">2</ge:metaMark>
</zone></ge:patch>
<ge:patch
type="newsprint"
binder="glue"
height="35"
width="90"> "The shores
on either side of the Sound are... The In- <zone>
<ge:metaMark function="sequence">3</ge:metaMark>
</zone></ge:patch>
</surface>
-
damageSpan/
(damaged span of text) marks the beginning of a longer sequence of text which is
damaged in some way but still legible.
group assigns an arbitrary number to each stretch of damage regarded as forming part of the same physical phenomenon. - gap (gap) indicates a point where material has been omitted in a transcription, whether for editorial reasons described in the TEI header, as part of sampling practice, or because the material is illegible, invisible, or inaudible.
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone>...</zone>
<damageSpan
hand="#author"
spanTo="#zoneEnd"
agent="knife_or_scissors"
group="1"
extent="3x5"
unit="cm"/>
<zone
ulx="9"
uly="20"
lrx="70"
lry="60"/>
<anchor xml:id="zoneEnd"/>
</surface>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone>...</zone>
</surface>
<damageSpan spanTo="#p3"/>
<gap extent="1" unit="folio">
<desc>Stub of a missing folio</desc>
</gap>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300"
xml:id="p3">
<zone>...</zone>
</surface></ge:document>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone>...</zone>
</surface>
<damageSpan spanTo="#P3" stage="#stage2"/>
<gap extent="1" unit="folio" stage="#stage2">
<desc>Stub of a missing folio</desc>
</gap>
<surface corresp="folio.xml#p1" stage="#stage1"/>
<surface corresp="folio.xml#p2" stage="#stage1"/>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300"
xml:id="P3">
<zone>...</zone>
</surface></ge:document>
3.2 Textual Alterations
Traces of authorial alteration (correction, addition, deletion, etc.) are frequently found within a single document, and may also be inferred when different documents are compared. It is however an open question as to whether inter-document discrepancies at the dossier level should be regarded in the same way as intra-document alterations. If two witnesses are collated, we may observe that a word present in one is missing from the other: does it necessarily follow that this is an addition or a deletion, which we would not hesitate to mark with an add or del tag if we are transcribing a single manuscript? We return to this question below.
- ‘meta-marks’, that is a kind of authorial markup present in the source and indicating how it should be read;
- additions, where a passage has been rewritten to fix or clarify it;
- deletions, where a passage had been struck through to indicate that it has been removed, or where a deletion has itself been cancelled
- transpositions, where passages have been reorganized or resequenced.
- add (addition) contains letters, words, or phrases inserted in the text by an author, scribe, annotator, or corrector.
- app (apparatus entry) contains one entry in a critical apparatus, with an optional lemma and at least one reading.
- corr (correction) contains the correct form of a passage apparently erroneous in the copy text.
- damage contains an area of damage to the text witness.
- del (deletion) contains a letter, word, or passage deleted, marked as deleted, or otherwise indicated as superfluous or spurious in the copy text by an author, scribe, annotator, or corrector.
- orig (original form) contains a reading which is marked as following the original, rather than being normalized or corrected.
- reg (regularization) contains a reading which has been regularized or normalized in some sense.
- restore indicates restoration of text to an earlier state by cancellation of an editorial or authorial marking or instruction.
- sic (latin for thus or so ) contains text reproduced although apparently incorrect or inaccurate.
- subst (substitution) groups one or more deletions with one or more additions when the combination is to be regarded as a single intervention in the text.
- supplied signifies text supplied by the transcriber or editor for any reason, typically because the original cannot be read because of physical damage or loss to the original.
- unclear contains a word, phrase, or passage which cannot be transcribed with certainty because it is illegible or inaudible in the source.
-
mod
represents any kind of modification identified within a text at a documentary level.
rend (rendition) indicates how the element in question was rendered or presented in the source text. type characterizes the element in some sense, using any convenient classification scheme or typology. -
modSpan/
represents any kind of modification identified
within a text at a documentary level, where this
extends over other XML markup constructs in the document.
spanTo indicates the end of a span initiated by the element bearing this attribute. -
metaMark
contains any textual or graphical mark in
a written text intended to signal how the text
should be read and not forming part of the text itself.
function describes the function (e.g. add, delete, alternate) of the mark. -
used/
a passage of text which has been marked as used, usually
meaning that it has been transcribed to a fair copy.
spanTo indicates the end of a span initiated by the element bearing this attribute. -
undo/
points to any marked-up intervention in a
text which has subsequently been
marked as to be cancelled or undone.
spanTo indicates the end of a span initiated by the element bearing this attribute. -
redo/
points to a marked-up intervention in a
text which has subsequently been
marked for a second time in a different way.
spanTo indicates the end of a span initiated by the element bearing this attribute. -
rewrite
contains a sequence of text which has been rewritten by the author, for
example by over-inking, to clarify or fix it.
cause documents the presumed cause of the repeated act of writing. - transposeGrp supplies a list of transpositions indicated at some point in the text, typically by means of metamarks.
- transpose describes a single textual transposition as an ordered list of at least two pointers specifying the order in which the elements indicated should be re-combined.
Most of these elements imply a certain level of semantic interpretation; for instance the usage of the add element to encode, say, interlinear insertions involves a decision that the interlinear text has been deliberately inserted rather than simply misplaced. As discussed above (see 1.4 Writing Acts vs. Text Stages), the use of these elements when transcribing from a documentary perspective is a pragmatic shortcut. In cases where it is felt desirable to keep the recording of ‘what is on the page’ entirely separate from ‘what is the editor’s interpretation’ (see 1.1 Fact vs. Interpretation), we provide two generic elements, <ge:mod> and <ge:modSpan>, which can be used to record any kind of modification identified in the document. These elements can be categorised by means of their type attribute, and visual aspects of their appearance can be described by means of the rend attribute, but they provide no further interpretation of the function or intention of the passage so marked up.
Whether such a modification, for instance a struck-out passage, is to be interpreted as a deletion or as some other phenomenon (e.g. as being already used) should be be expressed using the other, more semantically motivated, elements, which function at a different level of description.
3.2.1 Additions, fixations and clarifications
A writer may sometimes rewrite material a second time without significant change and in the same place. We consider this a distinct activity from addition as usually defined because no new textual material results but the status of existing material changes. We distinguish two variants of this: fixation where the first version was a tentative draft which is subsequently fixed, for example by inking it over; and clarification, where the first version was badly written and has been rewritten for clarity. The element <ge:rewrite> is provided to cover both cases.
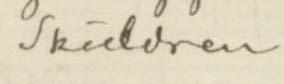

<add>get</add>
<del>but</del>
</subst>
<del stage="#s1" rend="overstrike">get</del> a young Heiress</ge:rewrite>
<ge:rewrite cause="fix" hand="#ja2" stage="#s1">Now...</ge:rewrite></ge:line>
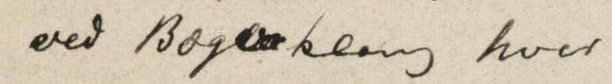
<ge:rewrite cause="unclear" stage="#stage1">er</ge:rewrite></ge:rewrite> ...</ge:line>
Metamarks and other markup-like strokes can also be inked over with the same purpose as the fixation or clarification of text passages. For instance, in a draft version of Goethe’s Faust, a passage was struck through once in pencil during one revision and then again with ink during a later revision, supposedly to fixate the deletion.
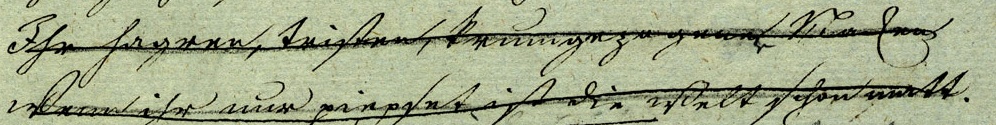
We propose an element redo (the opposite of undo, see 3.2.7 Undoing alterations), which can be used to encode this process as follows:
<ge:redo
xml:id="redo_3"
hand="#g_t"
target="#mod_1"
cause="fix"/>
<ge:modSpan
xml:id="mod_1"
rend="strikethrough"
spanTo="#anchor_1"
hand="#g_bl"/>Ihr hagren, triſten, krummgezog<ge:mod rend="strikethrough">nen</ge:mod>ener Nacken</ge:line>
<ge:line>Wenn ihr nur piepſet iſt die Welt ſchon matt.<anchor xml:id="anchor_1"/></ge:line>
3.2.2 Deletions and marked as used
In general, deletion in a source is marked using the del or delSpan element. However, it is useful to distinguish cases where a passage has been ‘indicated as superfluous or spurious in the copy text by an author, scribe, annotator, or corrector’ (TEI P5, s.v. del) from cases where a passage has been struck through or otherwise marked as having been used or copied to another location. In this latter case, the author does not intend to suppress the content, but only to mark that it has been transferred or reused. The element <ge:used> is provided to mark this kind of ‘deletion’.

<ge:used rend="cross" spanTo="#X2"/>
<zone>
<ge:line rend="underline">The Poet</ge:line>
<ge:line>
<del rend="strikethrough">I think</del> His sight is
the</ge:line>
<ge:line> sight of the ? and</ge:line>
<ge:line>has sent the instinct of the</ge:line>
<ge:line>? dog</ge:line>
</zone>
<zone>
<ge:line>I think <ge:rewrite>ten</ge:rewrite> million</ge:line>
<!-- ... -->
<ge:line>well; those <subst>
<del rend="strikethrough">supple-fingered gods</del>
<add>journeymen divine.</add>
</subst></ge:line>
<anchor xml:id="X2"/>
</zone>
</surface>
3.2.3 Metamarks
By metamark we mean marks such as numbers, arrows, crosses, or other symbols introduced by the writer into a document expressly for the purpose of indicating how the text is to be read. Such marks thus constitute a kind of markup of the document, rather than forming part of the text.
Unlike marginal notes or other additions to the text, meta-marks indicate a deliberate alteration of the writing (e.g. ‘move this passage over there’). We also consider as metamarks dates introduced to mark the beginning of a manuscript or a revision, but not forming part of it.
The <ge:metaMark> element carries a function attribute which specifies the function of the meta-mark and a target attribute which points to the element or elements concerned.

<ge:metaMark function="flag" target="#s1">lege</ge:metaMark>
<s xml:id="s1">Ock en schullen de bruwere des hilgen dages nicht over
<lb/>setten noch uppe den stillen fridach bruwen.</s>
<add>
<s>Noch nymande <lb/>over setten, se en sehin denne erst, dat uppe den
bonen <lb/>neyn stro noch, huw noch flaß ligghe, by pine eyner
halven <lb/>roden, deme bruwere so wol alse dem bruwheren to
murende.</s>
</add>
</del>

At regular points throughout the various drafts of the work, a number occurs, usually in the right margin (in this instance, "100"). These numbers result from the author counting the number of verse lines he has composed to the given point, and are not part of the text, but represent a stage at which Moore is taking stock of the progress of his composition.
<zone>
<!-- main zone -->
<ge:line>Be this she cried & wing’d her flight</ge:line>
<ge:line>My offering at the Gates of Bliss</ge:line>
<ge:line>
<del>Fully to know the odours <gap extent="1" unit="word" reason="illegible"/>
</del></ge:line>
<ge:line>
<del>Tho foul to heaven the vapour went</del></ge:line>
<ge:line>
<del>From vulgar</del>
<add>common</add>
<del>victors</del>, blood like this</ge:line>
<ge:line> Shed out for freedom, flows so bright. <ge:metaMark function="count">100</ge:metaMark></ge:line>
<ge:line> It would not stain the purest <subst>
<del>fount</del>
<add>rill</add>
</subst> .</ge:line>
<ge:line>“That sparkles thro the fields of light. <del>
<ge:metaMark function="count">100</ge:metaMark>
</del></ge:line>
<ge:line> Behold her in the skies again —</ge:line>
<ge:line>
<subst>
<del>But</del>
<add>And</add>
</subst>, tho so fleet her pinions bore</ge:line>
<ge:line> The spirit of the Warriors slain,</ge:line>
<ge:line>Now reach’d & pass’d the gates before her</ge:line>
</zone>
<zone>
<!-- left zone -->
<ge:line> Tho foul too oft the</ge:line>
<ge:line>tears that still</ge:line>
<ge:line>Tho foul the droppings <add>weepings</add></ge:line>
<ge:line>that distil</ge:line>
<ge:line>Tho foul the tears that</ge:line>
<ge:line>oft distil</ge:line>
<ge:line>From glory’s faulchion’</ge:line>
</zone>
</surface>
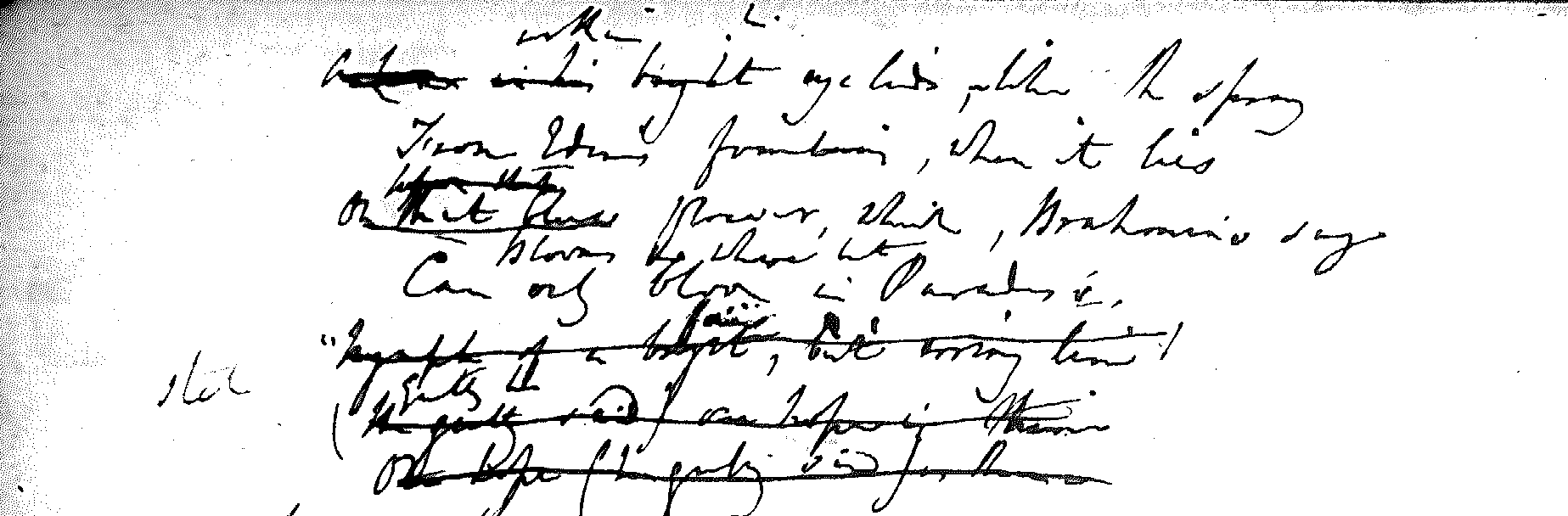
<zone>
<ge:line>
<gap extent="1" unit="word" reason="illegible"/>
<del>in his light</del>
<add>within</add> eyelids, within the spray</ge:line>
<ge:line>From Eden’s fountain, when it lies</ge:line>
<ge:line>
<hi rend="underline">On that blue</hi>
<del>before that</del> flower, which, Brahmins say</ge:line>
<ge:line> Can only <add>blooms nowhere but</add> bloom in
Paradise,</ge:line>
<ge:line>
<del xml:id="del1">“Nymph of a bright, fair but erring line!</del></ge:line>
<ge:line>
<ge:metaMark function="undo" target="#del1 #del2 #del3">stet</ge:metaMark>
<del xml:id="del2">(He gently <add>gently</add> he said) one hope
is thine</del></ge:line>
<ge:line>
<del xml:id="del3">One hope (he gently said) is thine</del></ge:line>
</zone>
</surface>

3.2.4 Alternative Readings
<ge:line>Alone <seg type="alternative" xml:id="alt1">before</seg>
<add place="above" type="alternative" xml:id="alt2">beside</add> his
native river —</ge:line>
<alt targets="#alt1 #alt2" mode="excl" weights="0 1"/>
</zone>
3.2.5 Transpositions
Metamarks are commonly used in the context of transposition, that is, the moving of words or blocks by the author to a different position using arrows, asterisks or numbers or other metamarks. One possible approach (used, for instance in HNML) would be to regard such transpositions as a special kind of substitution, and actually to represent the result of the transposition indicated by the metamarks in the encoding, for example by considering the segment previous to the transposition as deleted, and substituted by the one after the transposition.
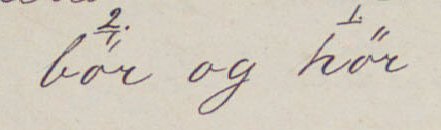
<seg xml:id="ib01">bör</seg>
<ge:metaMark
rend="underline"
function="transposition"
target="#ib1"
place="above">2.</ge:metaMark>
og <seg xml:id="ib02">hör</seg>
<ge:metaMark
rend="underline"
function="transposition"
target="#ib02"
place="above">1.</ge:metaMark></ge:line>
<ge:transposeGrp>
<ge:transpose>
<ptr target="#ib02"/>
<ptr target="#ib01"/></ge:transpose></ge:transposeGrp>

<ge:metaMark function="transposition" place="margin-left">2.)</ge:metaMark> thi da er du med Himmelen i
Pagt; — </ge:line>
<ge:line xml:id="ib4">
<ge:metaMark function="transposition" place="margin-left">1.)</ge:metaMark> da kan du Folkets Jøkelhjerter tine;</ge:line>
<ge:transposeGrp>
<ge:transpose>
<ptr target="#ib4"/>
<ptr target="#ib3"/></ge:transpose></ge:transposeGrp>
In case the area to be transposed is overlapping with some other kind of markup, the generic milestone can be used instead of seg or any other existing elements.
One or more transposeGrp elements may be supplied either embedded within the text or in the profileDesc of the header, depending on local preference. Each transposeGrp can contain one or more transpose element, each of which defines a single transposition.
3.2.6 Substitution
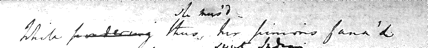
<del>pondering</del> thus <add>she
mus'd</add>
</subst>, her pinions fann'd</ge:line>
3.2.7 Undoing alterations
In some cases an author indicates that an alteration is itself to be altered: for example, a struck through passage may be restored via a dotted underlining, or the underlining of a passage may be deleted by a wavy line.

<ge:undo spanTo="#x2"/>si <anchor xml:id="x2"/> rechi a’</hi>
<del rend="overstrike">dotti</del>
<hi rend="underline">denti</hi> l’un d’essi cibi</ge:line>
To make explicit the relation between the undoing act and the initial act, we propose an alternative way of encoding these scribal acts, namely an empty <ge:undo> element, which points to the element the effect of which is being cancelled. If more than one (not coherent) part of the deletion is undone, more than one undo element will be needed, and each part undone must be given an identifier.
- s1 (initial): This is just some sample text, we need a real example.
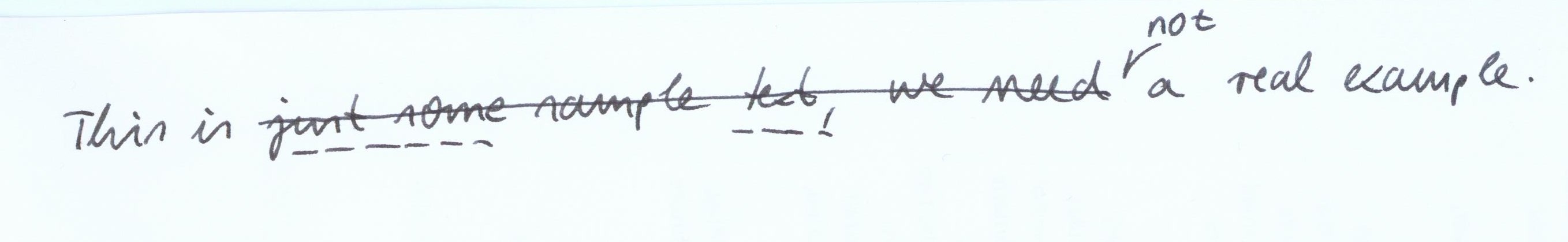
- s2: This is not a real example.
- s3: This is just some text, not a real example.
<ge:undo
target="#del_1"
spanTo="#X02"
rend="dotted"
stage="#s3"/>just some
<anchor xml:id="X02"/>sample <ge:undo
target="#del_1"
spanTo="#x4"
rend="dotted"
stage="#s3"/>text,<anchor xml:id="x4"/> we need
</del>
<add stage="#s2">not </add>a real example.</ge:line>
3.2.8 Instant corrections
The use of tags such as del and add necessarily implies that the modification concerned was made at some time after the original writing. An exception to this is where a false start or ‘instant’ correction has been identified: the author starts to write, and then immediately corrects what has been written. A special mechanism is provided for this case: an instant attribute has been introduced to att.editLike, whose datatype is data.xTruthValue and false is the default value. When the value of instant is true this indicates that the addition or deletion is considered to belong to the same writing stage as the rest of the unmodified document, while false means some stage later than the current stage.

- The letter T is written and then immediately deleted
- The word The is written, deleted, and replaced by the word His
- The added word His is then deleted
- The initial letter i of the words iron necklace is overwritten with a capital I
<del instant="true">T</del>
<subst>
<del>The</del>
<add place="above">
<del rend="overstrike">His</del>
</add>
</subst>
<subst>
<del rend="overwritten">i</del>
<add place="superimposed">I</add>
</subst>ron necklace</ge:line>
