
23 Using the TEI
Table of contents
This section discusses some technical topics concerning the deployment of the TEI markup scheme documented elsewhere in these Guidelines. In section 23.2 Personalization and Customization we discuss the scope and variety of the TEI customization mechanisms, distinguishing between ‘clean’ modifications, which result in a schema that supports a subset of the distinctions made in the full TEI system, on the one hand, from ‘unclean’ modifications, which result in a schema that does not have this property. In 23.3 Conformance we define the notion of TEI Conformance, distinguishing between documents which are algorithmically TEI conformant ("TEI Conformable") from those which are intrinsically conformant ("TEI Conformant"); we also define the concept of a TEI extension. Since the ODD markup description language defined in chapter 22 Documentation Elements is fundamental to the way conformance and customization are handled in the TEI system, these two definitional sections are followed by a section (23.4 Implementation of an ODD System) which describes the intended behaviour of an ODD processor.
23.1 Obtaining the TEI SchemasTEI: Obtaining the TEI Schemas¶
As discussed in chapter 22 Documentation Elements, the modules making up the TEI scheme are generated from a single set of XML source files. Schemas can be generated for TEI customizations in each of XML DTD language, W3C schema language, and RELAX NG schema language. In the body of the Guidelines, only the latter form is presented, using the compact syntax.
The TEI schemas and Guidelines are widely available over the Internet and elsewhere. The canonical home for the TEI source, the schema fragments generated from it, and example modifications, is the TEI repository at http://tei.sf.net; versions are also available in other formats, along with copies of the Guidelines and related materials, from the TEI web site at http://www.tei-c.org.
23.2 Personalization and CustomizationTEI: Personalization and Customization¶
These Guidelines provide an encoding scheme suitable for encoding a very wide range of texts, and capable of supporting a wide variety of applications. For this reason, the TEI scheme supports a variety of different approaches to solving similar problems, and also defines a much richer set of elements than is likely to be necessary in any given project. Furthermore, the TEI scheme may be extended in well-defined and documented ways for texts that cannot be conveniently or appropriately encoded using what is provided. For these reasons, it is almost impossible to use the TEI scheme without customizing or personalizing it in some way.
This section describes how the TEI encoding scheme may be customized, and should be read in conjunction with chapter 22 Documentation Elements, which describes how a specific application of the TEI encoding scheme should be documented. The documentation system described in that chapter is, like the rest of the TEI scheme, independent of any particular schema or document type definition language.
Formally speaking, these Guidelines provide both syntactic rules about how elements and attributes may be used in valid documents and semantic recommendations about what interpretation should be attached to a given syntactic construct. In this sense, they provide both a document type definition and a document type declaration. More exactly, we may distinguish between the TEI abstract model, which defines a set of related concepts, and the TEI schema which defines a set of syntactic rules and constraints. Many (though not all) of the semantic recommendations are provided solely as informal descriptive prose, though some of them are also enforced by means of such constructs as datatypes (see 1.4.2 Datatype Macros). Although the descriptions have been written with care, there will inevitably be cases where the intention of the contributors has not been conveyed with sufficient clarity to prevent users of the Guidelines from ‘extending’ them in the sense of attaching slightly variant semantics to them.
Beyond this unintentional semantic extension, some of the elements described can intentionally be used in a variety of ways; for example, the element note has an attribute type which can take on arbitrary string values, depending on how it is used in a document. A new type of ‘note’, therefore, requires no change in the existing model. On the other hand, for many applications, it may be desirable to constrain the possible values for the type attribute to a small set of possibilities. A schema modified in this way would no longer necessarily regard as valid the same set of documents as the corresponding unmodified TEI schema, but would remain faithful to the same conceptual model.
This section explains how the TEI scheme can be customized by suppressing elements, modifying classes of elements, adding elements, and renaming elements. Documents which validate against an application of the TEI scheme which has been customized in this way may or may not be considered ‘TEI conformant’, as further discussed in section 23.3 Conformance.
The TEI scheme is designed to support modification and customization in a documented way that can be validated by an XML processor. This is achieved by writing a small TEI Conformant document, from which an appropriate processor can generate both human-readable documentation, and a schema expressed in a language such as RELAX NG or DTD. The mechanisms used to instantiate a TEI schema differ for different schema languages, and are therefore not defined here. In XML DTDs, for example, extensive use is made of parameter entities, while in RELAX NG schemas, extensive use is made of patterns. In either case, the names of elements and, wherever possible, their attributes and content models are defined indirectly. The syntax used to implement this indirection also varies with the schema language used, but the underlying constructs in the TEI abstract model are given the same names.
- all the elements defined by the module (and described in the corresponding section of these Guidelines) are included in the schema;
- each such element is identified by the canonical name given it in these Guidelines;
- the content model of each such element is as defined by these Guidelines;
- the names, datatypes, and permitted values declared for each attribute associated with each such element are as given in these Guidelines;
- the elements comprising element classes and the meaning of macro declarations expressed in terms of element classes is determined by the particular combination of modules selected.
- particular elements may be suppressed, removing them from any classes in which they are members, and also from any generated schema;
- within certain limits, the name (generic identifier) associated with an element may be changed, without changing the semantic or syntactic properties of the element;
- new elements may be added to an existing class, thus making them available in macros or content models defined in terms of those classes;
- additional attributes, or attribute values, may be specified for an individual element or for classes of elements;
- within certain limits, attributes, or attribute values, may also be removed either from an individual element or for classes of elements;
- the characteristics inherited by one class from another class may be modified by modifying its class membership: all members of the class then inherit the changed characteristics;
- the set of values legal for an attribute or attribute class may be constrained or relaxed by supplying or modifying a value list, or by modifying its datatype.
The recommended way of implementing and documenting all such modifications is by means of the ODD system described in chapter 22 Documentation Elements; in the remainder of this section we give specific examples to illustrate how that system may be applied. An ODD processor, such as the Roma application supported by the TEI, or any other comparable set of stylesheets will use the declarations provided by an ODD to generate appropriate sets of declarations in a specific schema language such as RELAX NG or the XML DTD language. We do not discuss in detail here how this should be done, since the details are schema language-specific; some background information about the methods used for XML DTD and RELAX NG schema generation is however provided in section 1.2 Defining a TEI Schema. Several example ODD files are also provided as part of the standard TEI release: see further section 23.2.4 Examples of Modification below.
23.2.1 Kinds of ModificationTEI: Kinds of Modification¶
- deletion of elements;
- renaming of elements;
- modification of content models;
- modification of attribute and attribute-value lists;
- modification of class membership;
- addition of new elements.
Each kind of modification changes the set of documents that will be considered valid according to the resulting schema. Any combination of unchanged TEI modules may be thought of as defining a certain set of documents. Each schema resulting from a modified combination of TEI modules will define a different set of documents. The set of documents valid according to the unmodified schema may or may not be properly contained in the set of documents considered to be valid according to the modified schema. We use the term clean modification to describe a modification which regards as valid a subset of the documents considered valid by the same combination of TEI modules unmodified. Alternatively, the set of documents considered valid by the original schema might be disjoint from the set of documents considered valid by the modified schema, with neither being properly contained by the other. Modifications that have this result are called unclean modifications. Despite this terminology, unclean modifications are not particularly deprecated, and their use may often be vital to the success of a project. The concept is introduced solely to distinguish the effects of different kinds of modification.
Cleanliness can only be assessed with reference to elements in the TEI namespace.
23.2.1.1 Deletion of ElementsTEI: Deletion of Elements¶
The simplest way to modify the supplied modules is to suppress one or more of the supplied elements. This is simply done by setting the mode attribute to delete on an elementSpec for the element concerned.
<moduleRef key="core"/>
<!-- other modules used by this schema -->
<elementSpec ident="note" module="core" mode="delete"/>
</schemaSpec>
In most cases, deletion is a clean modification, since most elements are optional. Documents that are valid with respect to the modified schema are also valid according to the unmodified schema. To say this another way, the set of documents matching the new schema is contained by the set of documents matching the original schema.
There are however some elements in the TEI scheme which have mandatory children; for example, the element fileDesc must contain both a titleStmt and a sourceDesc. A modification which deleted either of these would be unclean, because it would regard as valid documents that the unmodified schema would regard as invalid. Deleting one of the many optional children of fileDesc (editionStmt or notesStmt for example) would not have this effect, and would be a clean modification.
In general, whenever the element deleted by a modification is mandatory within the content model of some other (undeleted) element, the result is an unclean modification, and may also break the TEI abstract model (23.3.3 Conformance to the TEI Abstract Model). However, the parent of a mandatory child can be safely removed if it is itself optional.
To determine whether or not an element is mandatory in a given context, the user must inspect the content model of the element concerned. In most cases, content models are expressed in terms of model classes rather than elements; hence, removing an element will generally be a clean modification, since there will generally be other members of the class available. If a class is completely depopulated by a modification, then the cleanliness of the modification will depend upon whether or not the class reference is mandatory or optional, in the same way as for an individual element.
23.2.1.2 Renaming of ElementsTEI: Renaming of Elements¶
Every element and other named markup construct in the TEI scheme has a canonical name, usually in the English language: this name is supplied as the value of the ident attribute on the elementSpec, attDef, classSpec, or macroSpec used to define it. The element or attribute declaration used within a schema generated from that specification may however be different, thus permitting schemas to be written using elements with generic identifiers from a different language, or otherwise modified. There may be many alternative identifiers for the same markup construct, and an ODD processor may choose which of them to use for a given purpose. Each such alternative name is supplied by means of an altIdent element within the specification element concerned.
<altIdent>annotation</altIdent>
</elementSpec>
Renaming in this way is always a reversible modification. Although it is an inherently unclean modification (because the set of documents matched by the resulting schema is disjoint with the set matched by its unmodified equivalent), the process of converting any document in which elements have been renamed into an exactly equivalent document using canonical names is completely deterministic, requiring only access to the ODD in which the renaming has been specified. This assumes that the renamed elements used are not placed in the TEI namespace but either use a null namespace or some user-defined namespace, as further discussed in 23.2.2 Modification and Namespaces; if this is not the case, care must be taken to avoid name collision between the new name and all existing TEI names. Furthermore, unclean modifications which do not specify a namespace are not conformant (see further 23.2 Personalization and Customization)
The TEI provides a systematic set of renamings into languages other than English. These all use a language-specific namespace.
23.2.1.3 Modification of Content ModelsTEI: Modification of Content Models¶
The content model for an element in the TEI scheme is defined by means of a content element within the elementSpec which specifies it. As shown elsewhere in these Guidelines, the content model is defined using RELAX NG syntax, whether the resulting schema is expressed in RELAX NG or in some other schema language.
<rng:ref name="macro.phraseSeq"/>
</content>
<content>
<rng:text/>
</content>
</elementSpec>
This is a clean modification which does not change the meaning of a TEI element; there is therefore no need to assign the element to some other namespace than that of the TEI, though it may be considered good practice; see further 23.2.2 Modification and Namespaces below.
A change of this kind, which simplifies the possible content of an element by reducing its model to one of its existing components, is always clean, because the set of documents matched by the resulting schema is a subset of the set of documents which would have been matched by the unmodified schema.
Note that content models are generally defined (as far as possible) in terms of references to model classes, rather than to explicit elements. This means that the need to modify content models is greatly reduced: if an element is deleted or modified, for example, then the deletion or modification will be available for every content model which references that element via its class, as well as those which reference it explicitly. For this reason it is not (in general) good practice to replace class references by explicit element references, since this may have unintended side effects.
An unqualified reference to an element class within a content model generates a content model which is equivalent to an alternation of all the members of the class referenced. Thus, a content model which refers to the model class model.phrase will generate a content model in which any one of the members of that class is equally acceptable. It is also possible to reference predefined content model fragments based on classes, such as ‘an optional repeatable alternation of all members of a class’, ‘a sequence containing no more than one of each member of the class’, etc. as described further in 22.4.6 Element Classes.
Content model changes which are not simple restrictions on an existing model should be undertaken with caution. The set of documents matching the schema which results from such changes is likely to be disjoint with the set of documents matching the unmodified schema, and such changes are therefore regarded as unclean. When content models are changed or extended, care should be taken to respect the existing semantics of the element concerned as stated in the Guidelines. For example, the element l is defined as containing a line of verse. It would not therefore make sense to redefine its content model so that it could also include members of the class model.pLike: such a modification although syntactically feasible would not be regarded as TEI conformant because it breaks the TEI abstract model.
23.2.1.4 Modification of Attribute and Attribute Value ListsTEI: Modification of Attribute and Attribute Value Lists¶
The attributes applicable to a given element may be specified in two ways: they may be given explicitly, by means of an attList element within the corresponding elementSpec, or they may be inherited from an attribute class, as specified in the classes element. To add a new attribute to an element, the schema builder should therefore first check to see whether this attribute is already defined by some existing attribute class. If it is, then the simplest method of adding it will be to make the element in question a member of that class, as further discussed below. If this is not possible, then a new attDef element must be added to the existing attList for the element in question.
Whichever method is adopted, the modification capabilities are the same as those available for elements. Attributes may be added or deleted from the list, using the mode attribute on attDef in the same way as on elementSpec. The ‘content’ of an attribute is defined by means of the datatype, valList, or valDesc elements within the attDef element. Any of these elements may be changed.
Suppose, for example, that we wish to add two attributes to the eg element (used to indicate examples in a text), type to characterize the example in some way, and source to indicate where the example comes from. A quick glance through the Guidelines indicates that the attribute class att.typed could be used to provide the type attribute, but there is no comparable class which will provide a source attribute. The existing eg element in fact has no local attributes defined for it at all: we will therefore need to add not only an attDef element to define the new attribute, but also an attList to hold it.
<attList>
<attDef
ident="source"
mode="add"
ns="http://www.example.org/ns/nonTEI">
<desc>specifies the source of an example by pointing to a
single bibliographic reference for it</desc>
<datatype maxOccurs="1">
<rng:ref name="data.pointer"/>
</datatype>
</attDef>
</attList>
</elementSpec>
The value supplied for the mode attribute on the attDef element is add; if this attribute already existed on the element we are modifying this should generate an error, since a specification cannot have more than one attribute of the same name. If the attribute is already present, we can replace the whole of the existing declaration by supplying replace as the value for mode; alternatively, we can change some parts of an existing declaration only by supplying just the new parts, and setting change as the value for mode.
Because the new attribute is not defined by the TEI, we must specify a namespace for it on the attDef; see further 23.2.2 Modification and Namespaces.
As noted above, adding the new type attribute involves changing this element's class membership; we therefore discuss that in the next section (23.2.1.5 Class Modification).
The canonical name for the new attribute is source, and is supplied on the ident attribute of the attDef element. In this simple example, we supply only a description and datatype for the new attribute; the former is given by the desc element, and the latter by the datatype element. (There are of course many other pieces of information which could be supplied, as documented in 22 Documentation Elements). The content of the datatype element, like that of the content element, uses patterns from the RELAX NG namespace, in this case to select one of the predefined TEI datatypes (1.4.2 Datatype Macros).
<attList>
<attDef ident="source" ns="http://example.com/ns" mode="add">
<desc>specifies the source of an example by supplying one of three
predefined codes for it.</desc>
<datatype maxOccurs="1">
<rng:ref name="data.word"/>
</datatype>
<valList type="closed">
<valItem ident="A">
<desc>Examples taken from the A-list</desc>
</valItem>
<valItem ident="B">
<desc>Examples taken from the B-list</desc>
</valItem>
<valItem ident="C">
<desc>Examples taken from the C-list</desc>
</valItem>
</valList>
</attDef>
</attList>
</elementSpec>
The same technique may be used to replace or extend the valList supplied as part of any attribute in the TEI scheme.
Depending on the modification, the set of documents matched by a schema generated from an ODD modified in this way, may or may not be a subset of the set of documents matched by the unmodified schema. As such, it is difficult to tell in principle whether such modifications are intrinsically unclean.
23.2.1.5 Class ModificationTEI: Class Modification¶
The concept of element classes was introduced in 1.3.2 Model Classes; an understanding of it is fundamental to successful use of the TEI scheme. As noted there, we distinguish model classes, the members of which all have structural similarity, from attribute classes, the members of which simply share a set of attributes.
The part of an element specification which determines its class membership is an element called classes. All classes to which the element belongs must be specified within this, using a memberOf element for each.
ident="eg"
module="tagdocs"
mode="change"
ns="http://example.com/ns">
<classes mode="change">
<memberOf key="att.typed"/>
</classes>
</elementSpec>
ident="term"
module="core"
mode="change"
ns="http://example.com/ns">
<classes mode="change">
<memberOf key="att.declaring" mode="delete"/>
</classes>
</elementSpec>
ident="term"
module="core"
mode="change"
ns="http://example.com/ns">
<classes mode="replace">
<memberOf key="att.interpLike"/>
</classes>
</elementSpec>
If however the mode attribute is set to change, the implication is that the memberships indicated by its child memberOf elements are to be combined with the existing memberships for the element.
<attList>
<attDef ident="rend" mode="delete"/>
</attList>
</classSpec>
The classes used in the TEI scheme are further discussed in chapter 1 The TEI Infrastructure. Note in particular that classes are themselves classified: the attributes inherited by a member of attribute class A may come to it directly from that class, or from another class of which A is itself a member. For example, the class att.global is itself a member of the classes att.global.linking and att.global.analytic. By default, these two classes are predefined as empty. However, if (for example) the linking module is included in a schema, a number of attributes (corresp, sameAs, etc.) are defined as members of the att.global.linking class. All elements which are members of att.global will then inherit these new attributes (see further section 1.3.1 Attribute Classes). A new attribute may thus be added to the global class in two ways: either by adding it to the attList defined within the class specification for att.global; or by defining a new attribute class, and changing the class membership of the att.global class to reference it.
Such global changes should be undertaken with caution: in general removing existing non-mandatory attributes from a class will always be a clean modification, in the same way as removing non-mandatory elements. Adding a new attribute to a class however can be a clean modification only if the new attribute is labelled as belonging to some namespace other than the TEI.
The same mechanisms are available for modification of model classes. Care should be taken when modifying the model class membership of existing elements since model class membership is what determines the content model of most elements in the TEI scheme, and a small change may have unintended consequences.
23.2.1.6 Addition of New ElementsTEI: Addition of New Elements¶
To add a completely new element into a schema involves providing a complete element specification for it, the classes element of which includes a reference to at least one TEI model class. Without such a reference, the new element will not be referenced by the content model of any other TEI element, and will therefore be inaccessible within a TEI document.
<classes>
<memberOf key="model.biblLike"/>
</classes>
<!-- other parts of the new declaration here -->
</elementSpec>
23.2.2 Modification and NamespacesTEI: Modification and Namespaces¶
All the elements defined by the TEI scheme are labelled as belonging to a single namespace, maintained by the TEI and with the URI http://www.tei-c.org/ns/1.0. 80 Only elements which are unmodified or which have undergone a clean modification may use this namespace. In a TEI-conformant document, it is assumed that all attributes not explicitly labelled with a namespace (such as, for example xml:id) also belong to the TEI namespace, and are defined by the TEI.
This implies that any other modification (including a renaming or reversible modification) must either specify a different namespace or specify no namespace at all. The ns attribute is provided on elements schemaSpec, elementSpec, and attDef for this purpose.
<attList>
<attDef ident="topic" mode="add" ns="http://www.example.org/ns/nonTEI">
<desc>indicates the topic of a TEI paragraph</desc>
<datatype>
<!-- ... -->
</datatype>
</attDef>
</attList>
</elementSpec>
<!-- ... -->
<p n="12" topic="rabbits">Flopsy, Mopsy, Cottontail, and
Peter...</p>
</div>
Since topic is explicitly labelled as belonging to something other than the TEI namespace, we regard the modification which introduced it as clean. A namespace-aware processor will be able to validate those elements in the TEI namespace against the unmodified schema. 81
Similar methods may be used if a modification (clean or unclean) is made to the content model or some other aspect of an element, or if it declares a new element.
<moduleRef key="header"/>
<!-- ... -->
</schemaSpec>
In addition to the TEI canonical namespace mentioned above, the TEI may also define namespaces for approved translations of the TEI scheme into other languages. These may be used as appropriate to indicate that a customization uses a standardized set of renamings. The namespace for such translations is the same as that for the canonical namespace, suffixed by the appropriate ISO language identifier (vi.1. Language identification). A schema specification using the Chinese translation, for example, would use the namespace http://www.tei-c.org/ns/1.0/zh
23.2.3 Documenting the ModificationTEI: Documenting the Modification¶
The elements used to define a TEI customization (schemaSpec, moduleRef, elementSpec, etc.) will typically be used within a TEI document which supplies further information about the intended use of the new schema, the meaning and application of any new or modified elements within it, and so on. This document will typically conform to a TEI (or other) schema which includes the module described in chapter 22 Documentation Elements. 82
Where the customization to be documented simply consists in a selection of modules, perhaps with some deletion of unwanted elements or attributes, the documentation need not specify anything further. Even here however it may be considered worthwhile to replace some of the semantic information provided by the unmodified TEI specification. For example, the desc element of an unmodified TEI elementSpec may describe an element in terms more general than appropriate to a particular project, or the exemplum elements within it may not illustrate the project's actual intended usage of the element, or the remarks element may contain discussions of matters irrelevant to the project. These elements may therefore be replaced or deleted within an elementSpec as necessary.
Radical revision is also possible. It is feasible to produce a modification in which the teiHeader or text elements are not required, or in which any other rule stated in these Guidelines is either not enforced or not enforceable. In fact, the mechanism, if used in an extreme way, permits replacement of all that the TEI has to say about every component of its scheme. Such revisions would result in documents that are not TEI conformant in even the broadest sense, and it is not intended that encoders use the mechanism in this way. We discuss exactly what is meant by the concept of TEI conformance in the next section, 23.3 Conformance.
23.2.4 Examples of Modification TEI: Examples of Modification ¶
- tei_bare
- The schema generated from this customization is the minimum needed for TEI Conformance. It provides only a handful of elements.
- tei_all
- The schema generated from this customization combines all available TEI modules, providing over 500 elements.
- tei_allPlus
- The schema generated from this customization combines all available TEI modules with three other non-TEI vocabularies, specifically MathML, SVG, and XInclude.
It is unlikely that any project would wish to use any of these extremes unchanged. However, they form a useful starting point for customization, whether by removing modules from tei_all or tei_allPlus, or by replacing elements deleted from tei_bare. They also demonstrate how an ODD document may be constructed to provide a basic reference manual to accompany schemas generated from it.
Shortly after publication of the first edition of these Guidelines, as a demonstration of how the TEI encoding scheme might be adopted to meet 90% of the needs of 90% of the TEI user community, the TEI editors produced a brief tutorial defining one specific ‘clean’ modification of the TEI scheme, which they called TEI Lite. This tutorial and its associated DTD became very popular and are still available from the TEI web site at http://www.tei-c.org/Guidelines/Customization/Lite/. The tutorial and associated schema specification is also included as one of the Exemplars provided with TEI P5.
The Exemplars provided with TEI P5 also include a customization file from which a schema for the validation of other customization files may be generated. This ODD, called tei_odds, combines the four basic modules with the tagdocs, dictionaries, gaiji, linking, and figures modules as well as including the (non-TEI) module defining the RELAX NG language. This enables schemas derived from this customization file to validate examples contained within them in a number of ways, further described within the document.
23.3 ConformanceTEI: Conformance¶
- interchange or integration of documents amongst different researchers or users;
- software specifications for TEI-aware processing tools;
- agreements for the deposit of texts in, and distribution of texts from, archives;
- specifying the form of documents to be produced by or for a given project.
In this section we explore several aspects of conformance, and in particular attempt to define how the term TEI Conformant should be used. The terminology defined here should be considered normative: users and implementors of the TEI Guidelines should use the phrases ‘TEI Conformant’, ‘TEI Conformable’, and ‘TEI Extension’ only in the senses given and with the usages described.
- is a well-formed XML document (23.3.1 Well-formedness criterion)
- can be validated against a TEI Schema, that is, a schema derived from the TEI Guidelines (23.3.2 Validation Constraint)
- conforms to the TEI Abstract Model (23.3.3 Conformance to the TEI Abstract Model)
- uses the TEI Namespace (and other namespaces where relevant) correctly (23.3.4 Use of the TEI Namespace)
- is documented by means of a TEI Conformant ODD file (23.3.5 Documentation Constraint) which refers to the TEI Guidelines
A document is said to be TEI Conformable if it is a well-formed XML document which can be transformed algorithmically and automatically into a TEI Conformant document as defined above without loss of information. Such a document may informally be described as TEI conformant; the terms algorithmically conformant or TEI Conformable are provided in order to distinguish documents exhibiting these kinds of conformance from others.
A document is said to use a TEI Extension if it is a well-formed XML document which is valid against a TEI Schema which contains additional distinctions, representing concepts not present in the TEI abstract model, and therefore not documented in these Guidelines. Such a document cannot, in general, be algorithmically conformant since it cannot be automatically transformed without loss of information. However, since one of the goals of the TEI is to support extensions and modifications, it should not be assumed that no TEI document can include extensions: an extension which is expressed by means of the recommended mechanisms is also a TEI document provided that those parts of it which are not extensions are TEI Conformant, or Conformable.
A TEI Conformant (or Conformable) document is said to follow TEI Recommended Practice if, wherever the Guidelines prefer one encoding practice to another, the preferred practice is used.
23.3.1 Well-formedness criterionTEI: Well-formedness criterion¶
These Guidelines mandate the use of well-formed XML as representation format. Documents must conform to the World Wide Web Consortium recommendation of the Extensible Markup Language (XML) 1.0 (Fourth Edition) or successor editions found at http://www.w3.org/TR/xml/. Other ways of representing the concepts of the TEI abstract model are possible, and other representations may be considered appropriate for use in particular situations (for example, for data capture, or project-internal processing). But such alternative representations are at best ‘TEI Conformable’, and cannot be considered in any way TEI Conformant.
Previous versions of these Guidelines used SGML as a representation format. With release P5, the only representation format supported by these Guidelines becomes valid XML; legacy documents in SGML format should therefore be converted using appropriate software.
A TEI Conformant document must use the TEI namespace, and therefore must also include an XML-conformant namespace declaration, as defined below (23.3.4 Use of the TEI Namespace).
The use of XML greatly reduces the need to consider hardware or software differences between processing environments when exchanging data. No special packing or interchange format is required for an XML document, beyond that defined by the W3C recommendations, and no special ‘interchange’ format is therefore proposed by these Guidelines. For discussion of encoding issues that may arise in the processing of special character sets or non-standard writing systems, see further chapter vi. Languages and Character Sets.
In addition to the well-formedness criterion, the W3C defines the notion of a valid document, as being a well-formed document which matches a specific set of rules or syntactic constraints, defined by a schema. As noted above, TEI conformance implies that the schema used to determine validity of a given document should be derived from the present Guidelines, by means of an ODD which references and documents the schema fragments which the Guidelines define.
23.3.2 Validation ConstraintTEI: Validation Constraint¶
All TEI Conformant documents must validate against a schema file that has been derived from the published TEI Guidelines, combined and documented in the manner described in section 23.2 Personalization and Customization. We call the formal output of this process a TEI Schema.
A TEI Schema may be expressed in any or all of the XML DTD language, W3C XML Schema, and RELAX NG (both compact and XML formats); the TEI does not mandate use of any particular schema language, only that this schema 83 should have been generated from a TEI ODD file that references the TEI Guidelines. Some of what is syntactically possible using the ODD formalism cannot be represented by all schema languages; and there are some features of some schema languages which have no counterpart in ODD. No single schema language fully captures all the constraints implied by conformance to the TEI abstract model. A document which is valid according to a TEI schema represented using one schema language may not be valid against the same schema expressed in other languages; in particular the DTD language does not fully support namespaces. Features which cannot be represented in all schema languages are documented in chapters 22 Documentation Elements and 23.4 Implementation of an ODD System.
As noted in section 23.2 Personalization and Customization, many varieties of TEI schema are possible and not all of them are necessarily TEI Conformant; derivation from an ODD is a necessary but not a sufficient condition for TEI Conformance.
23.3.3 Conformance to the TEI Abstract ModelTEI: Conformance to the TEI Abstract Model¶
The TEI Abstract Model is the conceptual schema instantiated by the TEI Guidelines. These Guidelines define, both formally and informally, a set of abstract concepts such as ‘paragraph’ or ‘heading’, and their structural relationships, for example stating that ‘paragraph’s do not contain ‘heading’s. These Guidelines also define classes of elements, which have both semantic and structural properties in common. Those semantic and structural properties are also a part of the TEI abstract model; the class membership of an existing TEI element cannot therefore be changed without changing the model. Elements can however be removed from a class by deletion, and new non-TEI elements within their own namespaces can be added to existing TEI classes.
23.3.3.1 Semantic ConstraintsTEI: Semantic Constraints¶
It is an important condition of TEI conformance that elements defined in the TEI Guidelines as having one specific meaning should not be used with another. For example, the element l is defined in the TEI Guidelines as containing a line of verse. A schema in which it is redefined to mean a typographic line, or an ordered queue of objects of some kind, cannot therefore be TEI Conformant, whatever its other properties.
The semantics of elements defined in the TEI Guidelines are conveyed in a number of ways, ranging from formally verifiable datatypes to informal descriptive prose. In addition, a mapping between TEI elements and concepts in other conceptual models may be provided by the equiv element where this is available.
A schema which shares equivalent concepts to those of the TEI conceptual model may be mappable to the TEI Schema by means of such a mechanism. For example, the concept of paragraph, expressed in the TEI scheme by the p element is probably the same concept as that expressed in the Docbook scheme by the <para> element. In this respect (though not in others) a Docbook-conformant document might therefore be considered to be TEI Conformable. Such areas of overlap facilitate interoperability, because elements from one namespace may be readily integrated with those from another, but do not affect the definition of conformance.
A document is said to conform to the TEI Abstract Model if features for which an encoding is proposed by the TEI Guidelines are encoded within it using the markup and other syntactic properties specified by means of a valid TEI Conformant schema. That is, the abstract definition and markup structurally correspond to that in the TEI Guidelines even if the names of elements and attributes might not. Although it may be possible to transform a document following the TEI Abstract Model into a TEI Conformant document, it is not itself conformant.
23.3.3.2 Mandatory Components of a TEI DocumentTEI: Mandatory Components of a TEI Document¶
- a single teiHeader element followed by a single text element, in that order; or
- in the case of a corpus or collection, a single overall teiHeader element followed by a series of TEI elements each with its own teiHeader
- Title Statement
- This should include the title of the TEI document expressed using a titleStmt element.
- Publication Statement
- This should include the place and date of publication or distribution of the TEI document, expressed using the publicationStmt element.
- Source Statement
- For a document derived from some previously existing document, this must include a bibliographic description of that source. For a document not so derived, this must include a brief statement that the document has no pre-existing source. In either case, this will be expressed using the sourceDesc element.
23.3.4 Use of the TEI NamespaceTEI: Use of the TEI Namespace¶
The Namespaces Recommendation of the W3C (Bray et al. (eds.) (2006)) provides a way for an XML document to combine markup from different vocabularies without risking name collision and consequent processing difficulties. While the scope of the TEI is large, there are many areas in which it makes no particular recommendation, or where it recommends that other defined markup schemes should be adopted, such as graphics or mathematics. It is also considered desirable that users of other markup schemes should be able to integrate documents using TEI markup with their own system. To meet these objectives without compromising the reliability of its encoding, a TEI Conformant document is required to make appropriate use of the TEI namespace.
Essentially all elements in a TEI Schema which represents concepts from the TEI abstract model belong to the TEI namespace, http://www.tei-c.org/ns/1.0, maintained by the TEI. A TEI Conformant document is required to declare the namespace for all the elements it contains whether these come from the TEI namespace or from other schemes.
A TEI Schema may be created which assigns TEI elements to some other namespace, or to no namespace at all. A document using such a schema must be regarded as a TEI extension and cannot be considered TEI Conformant, though it may be TEI Conformable. A document which places non-TEI elements or attributes within the TEI namespace cannot be TEI Conformant; such practices are strongly deprecated as they may lead to serious difficulties for processing or interchange.
23.3.5 Documentation ConstraintTEI: Documentation Constraint¶
As noted in 23.3.2 Validation Constraint above, a TEI Schema can only be generated from a TEI ODD, which also serves to document the semantics of the elements defined by it. A TEI Conformant document should therefore always be accompanied by (or refer to) a valid TEI ODD file specifying which modules, elements, classes, etc. are in use together with any modifications or renamings applied, and from which a TEI Schema can be generated to validate the document. The TEI supplies a number of predefined TEI Customization exemplar ODD files and the schemas already generated from them (see 23.2.4 Examples of Modification ), but most projects will typically need to customize the TEI beyond what these examples provide. It is assumed, for example, that most projects will customize the TEI scheme by removing those elements that are not needed for the texts they are encoding, and by providing further constraints on the attribute values and element content models the TEI provides. All such customizations must be specified by means of a valid TEI ODD file.
As different sorts of customization have different implications for the interchange and interoperability of TEI documents, it cannot be assumed that every customization will necessarily result in a schema that validates only TEI Conformant documents. The ODD language permits modifications which conflict with the TEI abstract model, even though observing this model is a requirement for TEI Conformance. The ODD language can in fact be used to describe many kinds of markup scheme, including schemes which have nothing to do with the TEI at all.
Equally, it is possible to construct a TEI Schema which is identical to that derived from a given TEI ODD file without using the ODD scheme. A schema can constructed simply by combining the predefined schema language fragments corresponding with the required set of TEI modules and other statements in the relevant schema language. The status of such a schema with respect to the tei_all schema cannot however be determined, in general; it may therefore be impossible to determine whether such a schema represents a clean modification or an extension. This is one reason for making the presence of a TEI ODD file a requirement for conformance.
23.3.6 Varieties of TEI ConformanceTEI: Varieties of TEI Conformance¶
- Is it a valid XML document, for which a TEI Schema exists? If not, then the document cannot be considered TEI Conformant in any sense.
- Is the document accompanied by a TEI Conformant ODD specification describing its markup scheme and intended semantics? If not, then the document can only be considered TEI Conformant if it validates against a predefined TEI Schema and conforms to the TEI abstract model.
- Does the markup in the document correctly represent the TEI abstract model? Though difficult to assess, this is essential to TEI conformance.
- Does the document claim that all of its elements come from some namespace other than the TEI (or no namespace)? If so, the document cannot be TEI Conformant, though it may be TEI Conformable.
- If the document claims to use the TEI namespace, in part or wholly, do the elements associated with that namespace in fact belong to it? If not, the document cannot be TEI Conformant; if so, and if all non-TEI elements and attributes are correctly associated with other namespaces, then the document may be TEI Conformant.
- Is the document valid according to a schema made by combining all TEI modules as well as valid according to the schema derived from its associated ODD specification? If so, the document is TEI Conformant.
- Is the document valid according to the schema derived from its associated ODD specification, but not according to tei_all? If so, the document uses a TEI extension.
- Is it possible automatically to transform the document into a document which is valid according to tei_all, using only information supplied in the accompanying ODD and without loss of information? If so, the document is TEI Conformable.
| A | B | C | D | E | F | G | H | |
| Conforms to TEI abstract model | Y | N | Y | Y | ? | Y | N | ? |
| Valid ODD present | Y | Y | Y | Y | Y | Y | Y | N |
| Uses only non-TEI namespace(s) or none | N | N | N | N | Y | N | Y | N |
| Uses TEI and other namespaces correctly | Y | Y | N | Y | N | Y | N | Y |
| Document is valid as a subset of tei_all | Y | N | Y | N | N | Y | N | Y |
| Document can be converted automatically to a form which is valid as a subset of tei_all | Y | N | Y | N | N | Y | N | ? |
We assume firstly that each sample document assessed here is a well-formed XML document, and that it is valid against some schema.
The document in column A is TEI Conformant. Its tagging follows the TEI Abstract Model, both as regards syntactic constraints (its l elements appear within div elements and not the reverse) and semantic constraints (its l elements appear to contain verse lines rather than typographic ones). It is accompanied by a valid ODD which documents exactly how it uses the TEI. All the TEI-defined elements and attributes in the document are placed in the TEI namespace. The schema against which it is valid is a ‘clean’ subset of the tei_all schema.
The document in column B is not a TEI document. Although it is accompanied by a valid TEI ODD, the resulting schema includes some ‘unclean’ modifications, and represents some concepts from the TEI Abstract Model using non-TEI elements; for example, it re-defines the content model of p to permit div within it, and it includes an element <pageTrimming> which appears to have the same meaning as the existing TEI fw element, but the equivalence is not made explicit in the ODD. It uses the TEI namespace correctly to identify the TEI elements it contains, but the ODD does not contain enough information automatically to convert its non-TEI elements into TEI equivalents.
The document in column C is TEI Conformable. It is almost the same as the document in column A, except that the names of the elements used are not those specified by the TEI namespace. Because the ODD accompanying it contains an exact mapping for each element name (using the altIdent element) and there are no name conflicts, it is possible to make an automatic conversion of this document.
The document in column D is a TEI Extension. It combines elements from its own namespace with unmodified TEI elements in the TEI namespace. Its usage of TEI elements conforms to the TEI Abstract Model. Its ODD defines a new <blort> element which has no exact TEI equivalent, but which is assigned to an existing TEI class; consequently its schema is not a clean subset of tei_all. If the associated ODD provided a way of mapping this element to an existing TEI element, then this would be TEI Conformable.
The document in column E is superficially similar to document D, but because it does not use any namespace declarations (or, equivalently, it assigns unmodified TEI elements to its own namespace), it may contain name collisions; there is no way of knowing whether a p within it is the same as the TEI's p or has some other meaning. The accompanying ODD file may be used to provide the human reader with information about equivalently named elements in the TEI namespace, and hence to determine whether the document is valid with respect to the TEI Abstract Model but this is not an automatable process. In particular, cases of apparent conflict (for example use of an element p to represent a concept not in the TEI Abstract Model but in the Abstract Model of some other system, whose namespace has been removed as well) cannot be reliably resolved. By our current definition therefore, this is not a TEI document.
The document in column F is TEI Conformable. The difference between it and that in column D is that the new element <blort> which is used in this document is a specialisation of an existing TEI element, and the ODD in which it is defined specifies the mapping (a <my:blort> may be automatically converted to a <tei:seg type="blort">, for example). For this to work, however, the <blort> must observe the same syntactic constraints as the seg; if it does not, this would also be a case of TEI Extension.
The document in column G is not a TEI document. Its structure is fully documented by a valid TEI ODD, but it does not claim to represent the TEI Abstract Model, does not use the TEI namespace, and is not intended to validate against any TEI schema.
The document in column H is very like that in column A, but it lacks an accompanying ODD. Instead, the schema used to validate it is produced simply by combining TEI schema fragments in the same way as an ODD processor would, given the ODD. If the resulting schema is a clean subset of tei_all, such a document is indistinguishable from a TEI Conformant one, but there is no way of determining (without inspection) whether this is the case if any modification or extension has been applied. Its status is therefore, like that of Text E, impossible to determine.
23.4 Implementation of an ODD SystemTEI: Implementation of an ODD System¶
This section specifies how a processing system may take advantage of the markup specification elements documented in chapter 22 Documentation Elements of these Guidelines in order to produce project specific user documentation, schemas in one or more schema languages, and validation tools for other processors.
The specifications in this section are illustrative but not normative. Its function is to further illustrate the intended scope and application of the elements documented in chapter 22 Documentation Elements, since it is believed that these may have application beyond the areas directly addressed by the TEI.
An ODD processing system has to accomplish two main tasks. A set of selections, deletions, changes, and additions supplied by an ODD customization (as described in 23.2 Personalization and Customization) must first be merged with the published TEI P5 ODD specifications. Next, the resulting unified ODD must be processed to produce the desired outputs.
An ODD processor is not required to do these two stages in sequence, but that may well be the simplest approach; the ODD processing tools currently provided by the TEI Consortium, which are also used to process the source of these Guidelines, adopt this approach.
23.4.1 Making a Unified ODDTEI: Making a Unified ODD¶
- schemaSpec (schema specification) generates a TEI-conformant schema and documentation for it.
ns (namespace) specifies the default namespace (if any) applicable to components of the schema. start specifies entry points to the schema, i.e. which elements are allowed to be used as the root of documents conforming to it. prefix specifies a prefix which will be appended to all patterns relating to TEI elements. This allows for external schemas to be mixed in which have elements of the same names as the TEI. targetLang (target language) specifies which language to use when creating the objects in a schema if names for elements or attributes are available in more than one language, . docLang (documentation language) specifies which languages to use when creating documentation if the description for an element, attribute, class or macro is available in more than one language, .
- specifications
- elements from the class model.oddDecl (by default elementSpec, classSpec, moduleSpec, and macroSpec); these must have a mode attribute which determines how they will be processed. 84 If the value of mode is add, then the object is simply copied to the output, but if it is change, delete, or replace, then it will be looked at by other parts of the process.
- references to specifications
- specGrpRef elements refer to specGrp elements that occur elsewhere in this, or another, document. A specGrp element, in turn, groups together a set of ODD specifications (among other things, including further specGrpRef elements). The use of specGrp and specGrpRef permits the ODD markup to occur at the points in documentation where they are discussed, rather than all inside schemaSpec. The target attribute of any specGrpRef should be followed, and the elementSpec, classSpec, and macroSpec, elements in the corresponding specGrp should be processed as described in the previous item; specGrpRef elements should be processed as described here.
- references to TEI Modules
- moduleRef elements with key attributes refer to components of the TEI. The value of the key attribute matches the ident attribute of the moduleSpec element defining a TEI module. The key must be dereferenced by some means, such as reading an XML file with the TEI ODD specification (either from the local hard drive or off the Web), or looking up the reference in an XML database (again, locally or remotely); whatever means is used, it should return a stream of XML containing the element, class, and macro specifications collected together in the specified module. These specification elements are then processed in the same way as if they had been supplied directly within the schemaSpec being processed.
- references to external modules
- a moduleRef element may also refer to a compatible external module by means of its url attribute; the content of such modules, which must be available in the RELAX NG XML syntax, are passed directly and without modification to the output schema when that is created.
- if there is an object in the ODD customization with the same value for the ident attribute, and a mode value of delete, then the object from the module is ignored;
- if there is an object in the ODD customization with the same value for the ident attribute, and a mode value of replace, then the object from the module is ignored, and the one from the ODD customization is used in its place;
- if there is an object in the ODD customization with the same value for the ident attribute, and a mode value of change, then the two objects must be merged, as described below;
- if there is an object in the ODD customization with the same value for the ident attribute, and a mode value of add, then an error condition should be raised;
- otherwise, the object from the module is copied to the result.
- Some components may occur only once within the merged object (for example attributes, and altIdent, content, or classes elements). If such a component is found in the ODD customization, it will be copied to the output; if it is not found there, but is present in the TEI ODD specification, then that will be copied to the output.
- Some components are grouping objects (attList, valList, for example); these are always copied to the output, and their children are then processed following the rules given in this list.
- Some components are ‘identifiable’: this means that they are members of the att.identified class from which they inherit the ident attribute; examples include attDef and valItem. A components of this type will be processed according to its mode attribute, following the rules given in this list.
- Some components may occur multiple times, but are neither grouped nor identifiable. Examples include the members of model.glossLike such as equiv, desc, gloss, the exemplum, remarks, listRef, datatype or defaultVal elements. These should be copied from both the TEI ODD specification and the ODD customization, and all occurrences included in the output.
<classes>
<memberOf key="att.typed"/>
</classes>
<content>
<!--…-->
</content>
</elementSpec>
<classes>
<memberOf key="att.typed"/>
</classes>
<content>
<!--… -->
</content>
<attList>
<attDef ident="subtype" mode="delete"/>
</attList>
</elementSpec>
<desc>marks paragraphs in prose.</desc>
<!--…-->
</elementSpec>
<desc xml:lang="es">marca párrafos en prosa.</desc>
<!--…-->
</elementSpec>
Similar considerations apply to multiple example elements, though these are less likely to cause problems in documentation. Note that existing examples can only be deleted by supplying a completely new elementSpec in replace mode, since the exemplum element is not identifiable.
<!--…-->
<content>
<rng:choice>
<rng:oneOrMore>
<rng:ref name="model.pLike"/>
</rng:oneOrMore>
<rng:zeroOrMore>
<rng:choice>
<rng:ref name="model.personPart"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
</rng:choice>
</content>
<!--…-->
</elementSpec>
<!--…-->
<content>
<rng:zeroOrMore>
<rng:choice>
<rng:ref name="model.pLike"/>
<rng:ref name="model.global"/>
<rng:ref name="figure"/>
<rng:ref name="figDesc"/>
<rng:ref name="model.graphicLike"/>
<rng:ref name="model.headLike"/>
</rng:choice>
</rng:zeroOrMore>
</content>
<!--…-->
</elementSpec>
The result of the work carried out should be a new schemaSpec which contains a complete and internally consistent set of element, class, and macro specifications, possibly also including moduleRef elements with url attributes identifying external modules.
23.4.2 Generating SchemasTEI: Generating Schemas¶
- all datatype and other macro specifications must be collected together and declared at the start of the output schema;
- all classes must be declared in the right order (since some classes reference others, the order is significant);
- all elements are declared;
- any moduleRef elements with a url attribute identifying an external schema must be processed.
- A RELAX NG (XML) schema is generated by creating wrappers around the content models taken directly from the ODD specification; a version re-expressed in the RELAX NG compact syntax is generated using James Clark's trang application.
- A DTD schema is generated by converting the RELAX NG content models to DTD language, often simplifying it to allow for the less-sophisticated output language.
- A W3C Schema schema is created by generating a RELAX NG schema and then using James Clark's trang application.
Other projects may decide to follow a different route, perhaps implementing a direct ODD to W3C Schema translator.
Secondly, it is possible to create two rather different styles of schema. On the one hand, the schema can try to maintain all the flexibility of ODD by using the facilities of the schema language for parameterization; on the other, it can remove all customization features and produce a flat result which is not suitable for further manipulation. The TEI project currently generates both styles of schema; the first as a set of schema fragments in DTD and RELAX NG languages, which can be included as modules in other schemas, and customized further; the second as the output from a processor such as Roma, in which many of the parameterization features have been removed.
<!-- ... -->
<classes>
<memberOf key="model.frontPart.drama"/>
</classes>
<content>
<rng:group>
<rng:zeroOrMore>
<rng:choice>
<rng:ref name="model.divTop"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
<rng:oneOrMore>
<rng:group>
<rng:ref name="model.common"/>
</rng:group>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</rng:oneOrMore>
<rng:zeroOrMore>
<rng:ref name="model.divBottom"/>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</rng:zeroOrMore>
</rng:group>
</content>
<!-- ... -->
</elementSpec>
In the remainder of these section, the terms simple schema and parameterized schema are used to distinguish the two schema types. An ODD processor is not required to support both, though the simple schema output is generally preferable for most applications.
<!--…-->
<content>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
<rng:optional>
<rng:ref name="speaker"/>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</rng:optional>
</content>
<!--…-->
</elementSpec>
<!--…-->
<content>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</content>
<!--…-->
</elementSpec>
Finally, an application will need to have some method of associating the schema with document instances that use it. The TEI does not mandate any particular method of doing this, since different schema languages and processors vary considerably in their requirements. ODD processors may wish to build in support for some of the methods for associating a document instance with a schema. The TEI does not mandate any particular method, but does suggest that those which are already part of XML (the DOCTYPE declaration for DTDs) and W3C Schema (the xsi:schemaLocation attribute) be supported where possible.
Note that declaration of the xsi:schemaLocation attribute in a W3C Schema schema is not permitted. Therefore, if W3C Schemas are being generated by converting the RELAX NG schema (for example, with trang), it may be necessary to perform that conversion prior to adding the xsi:schemaLocation declaration to the RELAX NG.
It is recognised that this is an unsatisfactory solution, but it permits users to take advantage of the W3C Schema facility for indicating a schema, while still permitting documents to be validated using DTD and RELAX NG processors without any conflict.
23.4.3 Names and Documentation in Generated SchemasTEI: Names and Documentation in Generated Schemas¶
- If a RELAX NG pattern or DTD parameter entity
is being created, its name is the value of
the corresponding ident attribute, prefixed by the value of any
prefix attribute on schemaSpec. This allows for
elements from an external schema to be mixed in without risk of name
clashes, since all TEI elements can be given a distinctive prefix
such as tei_.
Thus
<schemaSpec ident="test" prefix="tei_">may generate a RELAX NG (compact syntax) pattern like this:
<elementSpec ident="sp">
<!--...-->
</elementSpec>
</schemaSpec>tei_sp = element sp { ... }References to these patterns (or, in DTDs, parameter entities) also need to be prefixed with the same value. - If an element or attribute is being created, its default name is the value of the ident attribute, but if there is an altIdent child, its content is used instead.
- Where appropriate, the documentation strings in gloss
and desc should be copied into the generated schema. If there
is only one occurrence of either of these elements, it should be
used regardless, but if there are several, local processing rules will
need to be applied. For example, if there are several with different
values of xml:lang, a locale indication in the processing
environment might be used to decide which to use. For example,
<elementSpec module="core" ident="head">might generate a RELAX NG schema fragment like the following, if the locale is determined to be French:
<equiv/>
<gloss>heading</gloss>
<gloss xml:lang="fr">en-tête</gloss>
<gloss xml:lang="es">encabezamiento</gloss>
<gloss xml:lang="it">titolo</gloss>
<!-- ... -->
</elementSpec>head = ## en-tête element head { head.content, head.attributes }
- when a pattern for an attribute class is created, it is named after the attribute class identifier (as above) suffixed by .attributes (e.g. att.editLike.attributes);
- when a pattern for an attribute is created, it is named after the attribute class identifer (as above) suffixed by .attribute. and then the identifier of the attribute (e.g. att.editLike.attribute.resp);
- when a parameterized schema is created, each element generates patterns for its attributes and its contents separately, suffixing respectively .attributes and .contents to the element name.
23.4.4 Making a RELAX NG SchemaTEI: Making a RELAX NG Schema¶
To create a RELAX NG schema, the processor processes every macroSpec, classSpec, and elementSpec in turn, creating a RELAX NG pattern for each, using the naming conventions listed above. The order of declaration is not important, and a processor may well sort them into alphabetical order of identifier.
A complete RELAX NG schema must have an <rng:start> element defining which elements can occur as the root of a document. The ODD schemaSpec has an optional start attribute, containing one or more element names, which can be used to construct the <rng:start>.
23.4.4.1 MacrosTEI: Macros¶
<content>
<rng:zeroOrMore>
<rng:choice>
<rng:text/>
<rng:ref name="model.gLike"/>
<rng:ref name="model.phrase"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
</content>
</macroSpec>
<rng:zeroOrMore>
<rng:choice>
<rng:text/>
<rng:ref name="model.gLike"/>
<rng:ref name="model.phrase"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
</rng:define>
23.4.4.2 ClassesTEI: Classes¶
<!-- ... -->
</classSpec>
<rng:choice>
<rng:ref name="num"/>
<rng:ref name="measure"/>
<rng:ref name="measureGrp"/>
</rng:choice>
</rng:define>
<rng:ref name="num"/>
<rng:ref name="measure"/>
<rng:ref name="measureGrp"/>
</rng:define>
<rng:define name="model.measureLike_sequenceOptional">
<rng:optional>
<rng:ref name="num"/>
</rng:optional>
<rng:optional>
<rng:ref name="measure"/>
</rng:optional>
<rng:optional>
<rng:ref name="measureGrp"/>
</rng:optional>
</rng:define>
<rng:define
name="model.measureLike_sequenceOptionalRepeatable">
<rng:zeroOrMore>
<rng:ref name="num"/>
</rng:zeroOrMore>
<rng:zeroOrMore>
<rng:ref name="measure"/>
</rng:zeroOrMore>
<rng:zeroOrMore>
<rng:ref name="measureGrp"/>
</rng:zeroOrMore>
</rng:define>
<rng:define name="model.measureLike_sequenceRepeatable">
<rng:oneOrMore>
<rng:ref name="num"/>
</rng:oneOrMore>
<rng:oneOrMore>
<rng:ref name="measure"/>
</rng:oneOrMore>
<rng:oneOrMore>
<rng:ref name="measureGrp"/>
</rng:oneOrMore>
</rng:define>
<attList>
<attDef ident="enjamb" usage="opt">
<equiv/>
<desc>indicates whether the end of a verse line is marked by enjambement.</desc>
<datatype>
<rng:ref name="data.enumerated"/>
</datatype>
<valList type="open">
<valItem ident="no">
<equiv/>
<desc>the line is end-stopped
</desc>
</valItem>
<valItem ident="yes">
<equiv/>
<desc>the line in question runs on into the next
</desc>
</valItem>
<valItem ident="weak">
<equiv/>
<desc>the line is weakly enjambed
</desc>
</valItem>
<valItem ident="strong">
<equiv/>
<desc>the line is strongly enjambed</desc>
</valItem>
</valList>
</attDef>
</attList>
</classSpec>
<ref name="att.enjamb.attribute.enjamb"/>
<empty/>
</define>
<define xmlns="http://relaxng.org/ns/structure/1.0" name="att.enjamb.attribute.enjamb">
<optional>
<attribute name="enjamb">
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0">(enjambement) indicates whether the end of a verse line is marked by enjambement.
Sample values include: 1] no; 2] yes; 3] weak; 4] strong</a:documentation>
<ref name="data.enumerated"/>
</attribute>
</optional>
</define>
<defaultVal>yes</defaultVal>
<valList type="closed">
<valItem ident="yes">
<desc>the name component is spelled out in full.</desc>
</valItem>
<valItem ident="abb">
<gloss>abbreviated</gloss>
<desc>the name component is given in an abbreviated form.</desc>
</valItem>
<valItem ident="init">
<gloss>initial letter</gloss>
<desc>the name component is indicated only by one initial.</desc>
</valItem>
</valList>
</attDef>
<rng:optional>
<rng:attribute name="full" a:defaultValue="yes">
<rng:choice>
<rng:value>yes</rng:value>
<rng:value>abb</rng:value>
<rng:value>init</rng:value>
</rng:choice>
</rng:attribute>
</rng:optional>
</rng:define>
23.4.4.3 ElementsTEI: Elements¶
An elementSpec produces a RELAX NG specification in two parts; firstly, it must generate an <rng:define> pattern by which other elements can refer to it, and then it must generate an <rng:element> with the content model and attributes. It may be convenient to make two separate patterns, one for the element's attributes and one for its content model.
The content model is created simply by copying the body of the content element; the attributes are processed in the same way as those from attribute classes, described above.
23.4.5 Making a DTDTEI: Making a DTD¶
- declare all model classes which have a predeclare value of true
- declare all macros which have a predeclare value of true
- declare all other classes
- declare the modules (if DTD fragments are being constructed)
- declare any remaining macros
- declare the elements and their attributes
<desc>specifies the faith, religion, or belief set of a person.</desc>
<classes>
<memberOf key="model.persTraitLike"/>
<memberOf key="att.editLike"/>
<memberOf key="att.datable"/>
</classes>
<content>
<rng:ref name="macro.phraseSeq"/>
</content>
</elementSpec>
23.4.6 Generating DocumentationTEI: Generating Documentation¶
In Donald Knuth's literate programming terminology (Knuth (1992)), the previous sections have dealt with the tangle process; to generate documentation, we now turn to the weave process.
An ODD customization may consist largely of general documentation and examples, requiring no ODD-specific processing. It will normally however also contain a schemaSpec element and possibly some specGrp fragments.
The generated documentation may be of two forms. On the one hand, we may document the customization itself, that is, only those elements (etc.) which differ in their specification from that provided by the TEI reference documentation. Alternatively, we may generate reference documentation for the complete subset of the TEI which results from applying the customization. The TEI Roma tools take the latter approach, and operate on the result of the first stage processing described in 23.4.1 Making a Unified ODD.
Generating reference documentation for elementSpec, classSpec, and macroSpec elements is largely dependent on the design of the preferred output. Some applications may, for example, want to turn all names of objects into hyperlinks, show lists of class members, or present lists of attributes as tables, lists, or inline prose. Another technique implemented in these Guidelines is to show lists of potential ‘parents’ for each element, by tracing which other elements have them as possible members of their content models.
One model of display on a web page is shown in Figure 6, Example reference documentation for <faith>, corresponding to the faith element shown in section 23.4.5 Making a DTD.
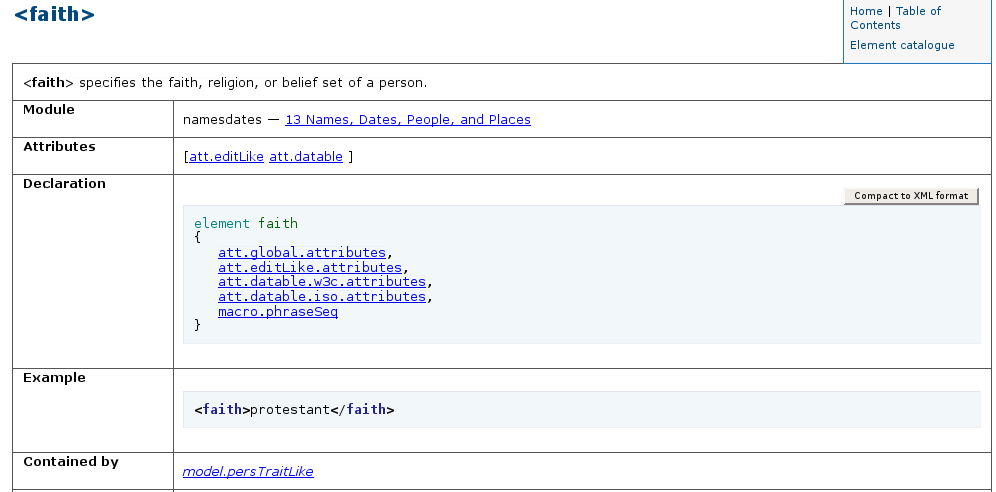
23.4.7 Using TEI Parameterized Schema FragmentsTEI: Using TEI Parameterized Schema Fragments¶
The TEI parameterized DTD and RELAX NG fragments make use of parameter entities and patterns for several purposes. In this section we describe their interface for the user. In general we recommend use of ODD instead of this technique.
23.4.7.1 Selection of ModulesTEI: Selection of Modules¶
Special-purpose parameter entities are used to specify which modules are to be combined into a TEI DTD. They take the form TEI.xxxxx where xxxx is the name of the module as given in table Table 1 in 1.1 TEI Modules. For example, the parameter entity TEI.linking is used to define whether or not to include the module linking. All such parameter entities are declared by default with the value IGNORE: to select a module, therefore, the encoder declares the appropriate parameter entities with the value INCLUDE.
For XML DTD fragments, note that some modules generate two DTD fragments: for example the analysis module generates fragments called analysis-decl and analysis. This is because the declarations they contain are needed at different points in the creation of an XML DTD.
The RELAX NG schema fragments can be combined in a wrapper schema using the standard mechanism of <rng:include> in that language.
23.4.7.2 Inclusion and Exclusion of ElementsTEI: Inclusion and Exclusion of Elements¶
The TEI DTD fragments also use marked sections and parameter entity references to allow users to exclude the definitions of individual elements, in order either to make the elements illegal in a document or to allow the element to be redefined. The parameter entities used for this purpose have exactly the same name as the generic identifier of the element concerned. The default definition for these parameter entities is INCLUDE but they may be changed to IGNORE in order to exclude the standard element and attribute definition list declarations from the DTD.
These parameter entities are defined immediately preceding the element whose declarations they control; because their names are completely regular, they are not documented further.
23.4.7.3 Changing the Names of Generic IdentifiersTEI: Changing the Names of Generic Identifiers¶
These declarations are generated by an ODD processor when TEI DTD fragments are created.
23.4.7.4 Embedding Local Modifications (DTD only)TEI: Embedding Local Modifications (DTD only)¶
Any local modifications to a DTD (i.e. changes to a schema other than simple inclusion or exclusion of modules) are made by declarations stored in one of two local extension files, one containing modifications to the TEI parameter entities, and the other new or changed declarations of elements and their attributes. Entity declarations must be made which associate the names of these two files with the appropriate parameter entity so that the declarations they contain can be embedded within the TEI DTD at an appropriate point.
- TEI.extensions.ent
- identifies a local file containing extensions to the TEI parameter entities
- TEI.extensions.dtd
- identifies a local file containing extensions to the TEI module
When an entity is declared more than once, the first declaration is binding and the others are ignored. The local modifications to parameter entities should therefore be handled before the standard parameter entities themselves are declared in tei.dtd. The entity TEI.extensions.ent is referred to before any TEI declarations are handled, to allow the user's declarations to take priority. If the user does not provide a TEI.extensions.ent entity, the entity will be expanded to the empty string.
For example the encoder might wish to add two phrase-level elements <it> and <bd>, perhaps as synonyms for <hi rend='italics'> and <hi rend='bold'>. As described in chapter 23.2 Personalization and Customization, this involves two distinct steps: one to define the new elements, and the other to ensure that they are placed into the TEI document structure at the right place.
Creating the new declarations is done in the same way for user-defined elements as for any other; the same parameter entities need to be defined so that they may be referenced by other elements. The content models of these new elements may also reference other parameter entities, which is why they need to be declared after other declarations.
↑ Contents « 22 Documentation Elements » Appendix A Model Classes