
11 Representation of Primary Sources
目次
- 11.1 Digital Facsimiles
- 11.2 Scope of Transcriptions
- 11.3 Altered, Corrected, and Erroneous Texts
- 11.4 Hands and Responsibility
- 11.5 Damage and Conjecture
- 11.6 Aspects of Layout
- 11.7 Headers, Footers, and Similar Matter
- 11.8 Other Primary Source Features not Covered in these Guidelines
- 11.9 Module for Transcription of Primary Sources
This chapter defines a module intended for use in the representation of primary sources, such as manuscripts or other written materials. Section 11.1 Digital Facsimiles provides elements for the encoding of digital facsimiles or images of such materials, while the remainder of the chapter discusses ways of encoding detailed transcriptions of such materials. It is expected that this module will also be useful in the preparation of critical editions, but the module defined here is distinct from that defined in chapter 12 Critical Apparatus, and may be used independently of it. Detailed metadata relating to primary sources of any kind may be recorded using the elements defined by the manuscript description module discussed in chapter 10 Manuscript Description, but again the present module may be used independently if such data is not required.
It should be noted that, as elsewhere in these Guidelines, this chapter places more emphasis on the problems of representing the textual components of a document than on those relating to the description of the document's physical characteristics such as the carrier medium or physical construction. These aspects, of particular importance in codicology and the bibliographic study of incunables, are touched on in the chapter on Manuscript Description (10 Manuscript Description) and also form the subject of ongoing work in the TEI Physical Bibliography workgroup.
Although this chapter discusses manuscript materials more frequently than other forms of written text, most of the recommendations presented are equally applicable mutatis mutandis in the encoding of printed matter or indeed any form of written source, including monumental inscriptions. Similarly, where in the following descriptions terms such as ‘scribe’, ‘author’, ‘editor’, ‘annotator’ or ‘corrector’ are used, these may be re-interpreted in terms more appropriate to the medium being transcribed. In printed material, for example, the ‘compositor’ plays a role analogous to the ‘scribe’, while in an authorial manuscript, the author and the scribe are the same person.
11.1 Digital FacsimilesTEI: Digital Facsimiles¶
These Guidelines are mostly concerned with the preparation of digital texts, in which a pre-existing text is transcribed or otherwise converted into character form, and marked up in XML. However, it is also very common practice to make a different form of ‘digital text’, which is instead composed of digital images of the original source, typically one per page, or other written surface. We call such a resource a digital facsimile. A digital facsimile may, in the simplest case, just consist of a collection of images, with some metadata to identify them and the source materials portrayed. It may sometimes contain a variety of images of the same source pages, for example of different resolutions, or of different kinds. Such a collection may form part of any kind of document, for example a commentary of a codicological or paeleographic nature, where there is a need to align explanatory text with image data. And it may also be complemented by a transcribed or encoded version of the original source, which may be linked to the page images. In this section we present elements designed to support these various possibilities and discuss the associated mechanisms provided by these Guidelines.
- att.global.facs 要素facsimileに含まれる画像や紙面に関する要素.
facs (facsimile) 当該要素に対応する要素facsimileにある画像やその部分への 参照.
<teiHeader>
<!--...-->
</teiHeader>
<text>
<pb facs="page1.png"/>
<!-- text contained on page 1 is encoded here -->
<pb facs="page2.png"/>
<!-- text contained on page 2 is encoded here -->
</text>
</TEI>
The recommended approach to encoding facsimiles is instead to use the facs attribute in conjunction with the elements facsimile, surface, and zone, which are also provided by this module. These elements make it possible to accommodate multiple images of each page, as well as to record arbitrary planar coordinates of textual elements on any kind of written surface and to link such elements with digital facsimile images of them. Typical applications include the provision of full text search in ‘digital facsimile editions’, and ways of annotating graphics, for example so as to identify individuals appearing in a group portraits and link them to data about the person represented.
- a TEI Header and a text element
- a TEI Header and a facsimile element
- a TEI Header, a facsimile element, and a text element
Like the text element, a facsimile element may also contain an optional front or back element, used in the same way as described in sections 4.5 Front Matter and 4.7 Back Matter.
<graphic url="page1.png"/>
<graphic url="page2.png"/>
<graphic url="page3.png"/>
<graphic url="page4.png"/>
</facsimile>
<graphic url="page1.png"/>
<surface>
<graphic url="page2-highRes.png"/>
<graphic url="page2-lowRes.png"/>
</surface>
<graphic url="page3.png"/>
<graphic url="page4.png"/>
</facsimile>
The surface element provides a way of indicating that the two images of page2 represent the same physical surface within the source material. A surface might be a sheet of paper or parchment, a face of a monument, a billboard, a membrane of a scroll, or indeed any two-dimensional surface, of any size.
- att.coordinated
2次元座標システムによる,場所を示す要素.
ulx 矩形における左上点のX軸の値を示す. uly 矩形における左上点のY軸の値を示す. lrx 矩形における右下点のX軸の値を示す. lry 矩形における右下点のY軸の値を示す.
The same coordinate space is used for a surface and for all of its child elements. 34 It may be most convenient to derive a coordinate space from a digital image of the surface in question such that each pixel in the image corresponds with a whole number of units (typically 1) in the coordinate space. In other cases it may be more convenient to use units such as millimetres; in neither case is any specific mapping to the physical dimensions of the object represented implied.
Each surface can contain one or more zone elements, each of which represents a rectangular region or bounding box defined in terms of the same coordinate space as that of its parent surface element. This provides a unit of analysis which may be used to define any rectangular region of interest, such as a detail or illustration, or some part of the surface which is to be aligned with a particular text element. The att.coordinated attributes listed above are also used to supply the coordinates of a zone.
As we have seen, a surface will usually correspond with the whole of a written surface. A zone, by contrast, defines any arbitrary rectangular area of interest using the same coordinate system. It might be bigger or smaller than its parent surface, or might overlap its boundaries. The only constraint is that it must be defined using the same coordinate system.
When an image of some kind is supplied within either a zone or a surface, the implication is that the whole of the image represents the zone or surface containing it. In the simple case therefore, we might imagine a surface defining a page, within which there is a graphic representing the whole of that page, and a number of zones defining parts of the page, each with its own graphic, each representing a part of the page. If however one of those graphics actually represents an area larger than the page (for example to include a binding or the surface of a desk on which the page rests), then it will be enclosed by a zone with coordinates larger than those of the parent surface.
Note that this mechanism does not provide any way of addressing a non-rectangular area, nor of coping with distortions introduced by perspective or parallax; if this is needed, the more powerful mechanisms provided by the Standard Vector Graphics (SVG) language should be used to define an overlay, as further discussed in 16.4.3 A Three-way Alignment.

<surface
ulx="50"
uly="20"
lrx="400"
lry="280">
<!-- ... -->
</surface>
</facsimile>
<surface
ulx="50"
uly="20"
lrx="400"
lry="280">
<zone
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</zone>
</surface>
</facsimile>
If desired, the binaryObject element described in 3.9 Graphics and other non-textual components (or any other element from the model.graphicLike class) may be used instead of a graphic element.
<surface
ulx="50"
uly="20"
lrx="210"
lry="280">
<desc>left hand page</desc>
<zone
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</zone>
</surface>
<surface
ulx="240"
uly="25"
lrx="400"
lry="280">
<desc>right hand page</desc>
<zone
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</zone>
</surface>
</facsimile>
<surface
ulx="50"
uly="20"
lrx="210"
lry="280">
<desc>Left hand page</desc>
<zone
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</zone>
<zone
ulx="90"
uly="40"
lrx="200"
lry="225">
<desc>Written part of left hand page</desc>
</zone>
</surface>
</facsimile>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
</surface>
</facsimile>

<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
<zone
ulx="25"
uly="25"
lrx="180"
lry="60">
<desc>contains the title</desc>
</zone>
<zone
ulx="28"
uly="75"
lrx="175"
lry="178"/>
<!-- contains the paragraph in italics -->
<zone
ulx="105"
uly="76"
lrx="175"
lry="160"/>
<!-- contains the figure -->
<zone
ulx="45"
uly="125"
lrx="60"
lry="130"/>
<!-- contains the word "pendans" -->
</surface>
</facsimile>
ulx="105"
uly="76"
lrx="175"
lry="160">
<graphic url="Bovelles49r-detail.png"/>
</zone>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone
xml:id="B49r"
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
</zone>
<zone
ulx="105"
uly="76"
lrx="175"
lry="160">
<graphic url="Bovelles49r-detail.png"/>
</zone>
<zone
xml:id="B49rHead"
ulx="25"
uly="25"
lrx="180"
lry="60"/>
<!-- contains the title -->
<zone
xml:id="B49rPara2"
ulx="28"
uly="75"
lrx="175"
lry="178"/>
<!-- contains the paragraph in italics -->
<zone
xml:id="B49rFig1"
ulx="105"
uly="76"
lrx="175"
lry="160"/>
<!-- contains the figure -->
<zone
xml:id="B49rW457"
ulx="45"
uly="125"
lrx="60"
lry="130"/>
<!-- contains the word "pendans" -->
</surface>
</facsimile>
<fw>De Geometrie 49</fw>
<head facs="#B49rHead">DU SON ET ACCORD DES CLOCHES ET <lb/> des alleures des chevaulx,
chariotz & charges, des fontaines:& <lb/> encyclie du monde,
& de la dimension du corps humain.</head>
<head>Chapitre septiesme</head>
<div n="1">
<p>Le son & accord des cloches pendans en ung mesme <lb/> axe, est
faict en contraires parties.</p>
<p rend="it" facs="#B49rPara2">LEs cloches ont quasi fi<lb/>gures de rondes
pyra<lb/>mides imperfaictes & <lb/> irregulieres: & leur
accord se <lb/> fait par reigle geometrique. Com<lb/>me si les deux
cloches C & D <lb/> sont <w facs="#B49rW457">pendans</w> à ung
mesme axe <lb/> ou essieu A B: je dis que leur ac<lb/>cord se fera en
co<ex>n</ex>traires parties<lb/> co<ex>m</ex>me voyez icy
figuré. Car qua<ex>n</ex>d <lb/> lune sera en hault, laultre
declinera embas. Aultrement si elles decli<lb/>nent toutes deux
ensembles en une mesme partie, elles seront discord, <lb/> & sera
leur sonnerie mal plaisante à oyr.<figure facs="#B49rFig1">
<graphic url="Bovelles49r-detail.png"/>
</figure>
</p>
</div>
Further discussion of the encoding choices made in the above transcription is provided in the remainder of this chapter.
<surface start="#PB49R">
<graphic url="Bovelles-49r.png"/>
</surface>
</facsimile>
<text>
<!-- ... -->
<pb xml:id="PB49R"/>
<fw>De Geometrie 49</fw>
<!-- ... -->
</text>
11.2 Scope of TranscriptionsTEI: Scope of Transcriptions¶
- first, methods of recording editorial or other alterations to the text, such as expansion of abbreviations, corrections, conjectures, etc. (section 11.3 Altered, Corrected, and Erroneous Texts)
- then, methods of describing important extra-linguistic phenomena in the source: unusual spaces, lines, page and line breaks, change of manuscript hand, etc. (section 11.4 Hands and Responsibility)
- finally, a method of recording material such as running heads, catch-words, and the like (section 11.7 Headers, Footers, and Similar Matter)
These recommendations are not intended to meet every transcriptional circumstance likely to be faced by any scholar. Rather, they should be regarded as a base which can be elaborated if necessary by different scholars in different disciplines.
As a rule, all elements which may be used in the course of a transcription of a single witness may also be used in a critical apparatus, i.e. within the elements proposed in chapter 12 Critical Apparatus. This can generally be achieved by nesting a particular reading containing tagged elements from a particular witness within the rdg element in an app structure.
Just as a critical apparatus may contain transcriptional elements within its record of variant readings in various witnesses, one may record variant readings in an individual witness by use of the apparatus mechanisms app and rdg. This is discussed in section 12.3 Using Apparatus Elements in Transcriptions.
11.3 Altered, Corrected, and Erroneous TextsTEI: Altered, Corrected, and Erroneous Texts¶
In the detailed transcription of any source, it may prove necessary to record various types of actual or potential alteration of the text: expansion of abbreviations, correction of the text (either by author, scribe, or later hand, or by previous or current editors or scholars), addition, deletion, or substitution of material, and the like. The sections below describe how such phenomena may be encoded using either elements defined in the core module (defined in chapter 3 Elements Available in All TEI Documents) or specialized elements available only when the module described in this chapter is available.
11.3.1 Core elements for Transcriptional WorkTEI: Core elements for Transcriptional Work¶
- abbr 名称の省略
- add 著者,筆写者,注釈者,校正者による,文字,単語,句レベルでのテキスト 挿入を示す.
- choice テキスト中の同じ場所で,異なる符号化記述をまとめる.
- corr 元資料中の明らかな間違いを正したものを示す.
- del 著者・筆写者・注釈者・校正者により,削除または削除として符号化または 余分なものまたは間違いとして示されている,文字,単語,句を示す.
- expan 省略形の元の表現を示す.
- gap (gap) TEIヘダーにある編集上の理由,または当該資料が判読できない・聞こえな いことを理由に,転記の際に省略された部分の場所を示す.
- sic (latin for thus or so ) 明らかに間違い,不正確ではあるが,そのまま収録してあるテキスト.
- att.editLike 学術的調整・解釈の性質を表す属性を示す.
evidence 当該解釈や調整の信頼度や正確さを判断する証拠を示す. source 当該読みの元になる資料を示す,ひとつ以上のポインタ. - att.responsibility provides attributes indicating who is responsible for
something asserted by the markup and the degree of certainty
associated with it.
cert (certainty) 当該解釈や調整の確信度を示す. resp (responsible party) 当該解釈や調整の責任者を示す.例えば,編集者,翻訳者など. - att.typed
要素を分類するための属性を示す.
type 当該要素の分類を示す. subtype 必要であれば,当該要素の下位分類を示す.
The following sections describe how the core elements just named may be used in the transcription of primary source materials.
11.3.2 Abbreviation and ExpansionTEI: Abbreviation and Expansion¶
The writing of manuscripts by hand lends itself to the use of abbreviation to shorten scribal labour. Commonly occurring letters, groups of letters, words, or even whole phrases, may be represented by significant marks. This phenomenon of manuscript abbreviation is so widespread and so various that no taxonomy of it is here attempted. Instead, methods are shown which allow abbreviations to be encoded using the core elements mentioned above.
A manuscript abbreviation may be viewed in two ways. One may transcribe it as a particular sequence of letters or marks upon the page: thus, a ‘p with a bar through the descender’, a ‘superscript hook’, a ‘macron’. One may also interpret the abbreviation in terms of the letter or letters it is seen as standing for: thus, ‘per’, ‘re’, ‘n’. Both of these views are supported by these Guidelines.
In many cases the glyph found in the manuscript source also exists in the Unicode character set: for example the common Latin brevigraph ⁊, standing for et and often known as the ‘Tironian et’ can be directly represented in any XML document as the Unicode character with code point U+204A (see further Character References and vi.1. Language identification). In cases where it does not, these Guidelines recommend use of the g element provided by the gaiji module described in chapter 5 Representation of Non-standard Characters and Glyphs. This module allows the encoder great flexibility both in processing and in documenting non-standard characters or glyphs, including the ability to provide detailed documentation and images for them.
ladder
<!-- elsewhere -->
<charDecl>
<char xml:id="b-er">
<!-- definition for the er brevigraph -->
</char>
<char xml:id="b-per">
<!-- definition for the per brevigraph -->
</char>
</charDecl>
<abbr>
<g ref="#b-per">per</g>sone
</abbr>
...
<expan>persone</expan> ...
<abbr>eu<g ref="#b-er">er</g>y</abbr>
<expan>euery</expan>
</choice>
<g ref="#b-er"/>
</am>y</abbr>
<abbr>
<am>
<g ref="#b-per"/>
</am>sone
</abbr> ...
<expan>
<ex>per</ex>sone
</expan> ...
<am>
<g ref="#b-er"/>
</am>
<ex>er</ex>
</choice>y
<choice>
<am>
<g ref="#b-per"/>
</am>
<ex>per</ex>
</choice>sone ...
As implied in the preceding discussion, making decisions about which of these various methods of representing abbreviation to use will form an important part of an encoder's practice. As a rule, the abbr and am elements should be preferred where it is wished to signify that the content of the element is an abbreviation, without necessarily indicating what the abbreviation may stand for. The ex and expan elements should be used where it is wished to signify that the content of the element is not present in the source but has been supplied by the transcriber, without necessarily indicating the abbreviation used in the original. The decision as to which course of action is appropriate may vary from abbreviation to abbreviation; there is no requirement that the one system be used throughout a transcription, although doing so will generally simplify processing. The choice is likely to be a matter of editorial policy. If the highest priority is to transcribe the text literatim, while indicating the presence of abbreviations, the choice will be to use abbr or am throughout. If the highest priority is to present a reading transcription, while indicating that some letters or words are not actually present in the original, the choice will be to use ex or expan throughout.
plural ending (-es, -is, -ys>) but the singular <hi rend="it">good</hi> was used with the meaning <q>property</q>,
<q>wealth</q>, at this time (v. examples quoted in OED, sb. Good,
C. 7, b, c, d and 8 spec.)</note>
good<ex resp="#mp" cert="high">e</ex> I was welbeloued
<resp>Editorial emendations</resp>
<name>Malcom Parkes</name>
</respStmt>
<choice>
<sic>good<abbr>ɽ</abbr>
</sic>
<expan resp="#mp" cert="high">good<ex>e</ex>
</expan>
</choice>
I was welbeloued
If more than one expansion for the same abbreviation is to be recorded, multiple notes may be supplied. It may also be appropriate to use the markup for critical apparatus; an example is given in section 12.3 Using Apparatus Elements in Transcriptions.
11.3.3 Correction and ConjectureTEI: Correction and Conjecture¶
has been modified by James to begin ‘But One must ...’, without the inital capital O having been reduced to lowercase. This non-standard orthography could be recorded thus:One must have lived longer with this system, to appreciate its advantages.
must have lived ...
have lived ...
<choice>
<sic>One</sic>
<corr>one</corr>
</choice> must have lived
...
et <choice>
<sic>angues</sic>
<corr>augens</corr>
</choice>.
Note that the corr element is used to provide a corrected form which is not present in the source; in the case of a correction made in the source itself, whether scribal, authorial, or by some other hand, the add, del, and subst elements described in 11.3.4 Additions and Deletions should be used.
create nothing <supplied>we</supplied> develope.
As with expan and abbr, the choice as to whether to record simply that there is an apparent error, or simply that a correction has been applied, or to record both possible readings within a choice element is left to the encoder. The decision is likely to be a matter of editorial policy, which might be applied consistently throughout or decided case by case. If the highest priority is to present an uncorrected transcription while noting perceived errors in the original, the choice will typically be to use only sic throughout. If the highest priority is to present a reading transcription, while indicating that perceived errors in the original have been corrected, the choice will be to use only corr throughout.
Further information may be attached to instances of these elements by the note element and resp and cert attributes. Instances of these elements may also be classified according to any convenient typology using the type attribute.
Were membres maad, of generacioun
And of so parfit wis a
<choice xml:id="corr117">
<sic>wight</sic>
<corr>wright</corr>
</choice>
ywroght?
<!-- ... -->
<note target="#corr117">This emendation of the Hengwrt copy text,
based on a Latin source and on the reading of three late
and usually unauthoritative manuscripts, was proposed
by E. Talbot Donaldson in <bibl>
<title>Speculum</title> 40 (1965)
626–33.</bibl>
</note>
<!-- somewhere in the header ... --><name xml:id="ETD">E Talbot Donaldson</name>
<!-- ... -->
And of so parfit wis a
<choice>
<sic>wight</sic>
<corr resp="#ETD" cert="medium">wright</corr>
</choice>
ywroght?
<sic>mens</sic>
<corr>iners</corr>
</choice> que nutu dei
gesta sunt ... unde esset uiriliter
<choice xml:id="sic-2">
<corr>uegetata</corr>
<sic>negata</sic>
</choice>
graphically what the scribe should be copying but which does not make
sense in the context.</note>
<choice>
<sic>mens</sic>
<corr type="graphSubs">iners</corr>
</choice> que nutu dei
gesta sunt ... unde esset uiriliter
<choice>
<corr type="graphSubs">uegetata</corr>
<sic>negata</sic>
</choice>
<choice>
<sic>mens</sic>
<corr type="graphSubs">iners</corr>
<corr type="reversal">inres</corr>
</choice> que nutu dei
gesta sunt ...
<p>The following codes are used to categorise corrections identified
in this transcription:
<list type="gloss">
<label>graphSubs</label>
<item>Substitution of a more familiar word which resembles
graphically what the scribe should be copying but which does not make
sense in the context.</item>
<!-- ... -->
</list>
</p>
</correction>
For a given project, it may well be desirable to limit the possible values for the type or subtype attributes automatically. This is easily done but requires customization of the TEI system using techniques described in 23.2 Personalization and Customization, in particular 23.2.1.4 Modification of Attribute and Attribute Value Lists, which should be consulted for further information on this topic.
<choice>
<sic>wight</sic>
<corr resp="#mp" source="#Gg">wyf</corr>
</choice>
ywroght?
<msIdentifier>
<settlement>Cambridge</settlement>
<repository>University Library</repository>
<idno>Gg.1. 27</idno>
</msIdentifier>
<!-- further description of the manuscript here -->
</msDesc>
parfit wis a
<app>
<rdg wit="#Hg">wight</rdg>
<rdg wit="#Ln #Ry2 #Ld">wright</rdg>
<rdg wit="#Gg">wyf</rdg>
</app>
parfit wis a
<app>
<rdg wit="#Hg">wight</rdg>
<rdg wit="#Ln #Ry2 #Ld">
<corr resp="#ETD">wright</corr>
</rdg>
<rdg wit="#Gg">
<corr resp="#mp">wyf</corr>
</rdg>
</app>
Like the resp attribute, the cert attribute may be used with both corr and rdg elements. When used on the rdg element, these attributes indicate confidence in and responsibility for identifying the reading within the sources specified; when used on the corr element they indicate confidence in and responsibility for the use of the reading to correct the base text. If no other source is indicated (either by the source attribute, or by the wit attribute of a parent rdg), the reading supplied within a corr has been provided by the person indicated by the resp attribute.
If it is desired to express aspects of certainty and responsibility for some other aspect of the use of these elements, then the mechanisms discussed in chapter 21 Certainty, Precision, and Responsibility may be found useful. See also 11.4.2 Hand, Responsibility, and Certainty Attributes for further discussion of the issues of certainty and responsibility in the context of transcription.
11.3.4 Additions and DeletionsTEI: Additions and Deletions¶
- add 著者,筆写者,注釈者,校正者による,文字,単語,句レベルでのテキスト 挿入を示す.
- addSpan/ (added span of text) 著者,筆写者,注釈者,校正者の手による長めの追加テキストを挿入する始 点を示す(addも参照のこと).
- del 著者・筆写者・注釈者・校正者により,削除または削除として符号化または 余分なものまたは間違いとして示されている,文字,単語,句を示す.
- delSpan/ 著者・筆写者・注釈者・校正者により,削除または削除として符号化または 余分なものまたは間違いとして示されている,長めのテキスト部分の始点を 示す.
- att.spanning
テキスト幅の範囲を内容としてではなく参照機能を使って示す要素に付与さ
れる属性を示す.
spanTo 当該要素が示す範囲の終点を示す.
- att.transcriptional
手書き資料や同様の資料を転記する場合,著者や筆写者に関する調整を記録
する要素に付与される属性を示す.
seq (sequence) 当該属性が示す素性が出現すると想定されている順番の,番号を示す. status 当該調整の影響を示す.例えば,削除の際,取消線の範囲が多すぎた り少なすぎたりする場合や,追加の際,既にあるテキストの部分をコピー して挿入したりする場合. hand 当該調整を行った主体の筆致を特定する.
sight. Others — and here is one of them — <add hand="#mb">do
ever</add> improve by recognition ....
<handNote xml:id="mb">Max Beerbohm holograph</handNote>
...
<handNote xml:id="dhl">D H Lawrence holograph</handNote>
If deletions are classified systematically, the type attribute may be useful to indicate the classification; when they are classified by the manner in which they were effected, or by their appearance, however, this will lead to a certain arbitrariness in deciding whether to use the type or the rend attribute to hold the information. In general, it is recommended that the rend attribute be used for description of the appearance or method of deletion, and that the type attribute be reserved for higher level or more abstract classifications.

<person xml:id="RG">
<!-- information about Robert Graves here -->
</person>
</listPerson>
precedents <del hand="#RG">in the</del>: current,
obsolete, <add hand="#RG" place="above">cant,</add>
cataphretic and nonce-words are all included.
<del>for an abridgement</del>
</add>in
explanation...
are all included. <del hand="#RG">It is</del>
<subst>
<add>T</add>
<del>t</del>
</subst>he expressed
The add and del elements defined in the core module suffice only for the description of additions and deletions which fit within the structure of the text being transcribed, that is, which each deletion or addition is completely contained by the structural element (paragraph, line, division) within which it occurs. Where this is not the case, for example because an individual addition or deletion involves several distinct structural subdivisions, such as poems or prose items, or otherwise crosses a structural boundary in the text being encoded, special treatment is needed. The addSpan and delSpan elements are provided by this module for that purpose. (For a general discussion of the issue see further 20 Non-hierarchical Structures).
<!-- ... -->
<body>
<div>
<!-- text here -->
</div>
<addSpan n="added gathering" hand="#heol" spanTo="#p025"/>
<div>
<!-- text of first added poem here -->
</div>
<div>
<!-- text of second added poem here -->
</div>
<div>
<!-- text of third added poem here -->
</div>
<div>
<!-- text of fourth added poem here -->
</div>
<anchor xml:id="p025"/>
<div>
<!-- more text here -->
</div>
</body>
<delSpan spanTo="#EPdelEnd" resp="#EP" rend="strikethrough"/>
<l>To where Saint Mary Woolnoth kept the time,</l>
<l>With a dead sound on the final stroke of nine.</l>
<anchor xml:id="EPdelEnd"/>
<l>There I saw one I knew, and stopped him, crying "Stetson!</l>...
<delSpan rend="verticalStrike" spanTo="#delend01"/>
Tis moonlight <del>upon</del>
<add>over</add> Oman's sky
</l>
<l>Her isles of pearl look lovelily<anchor xml:id="delend01"/>
</l>
The text deleted must be at least partially legible, in order for the encoder to be able to transcribe it. If all of part of it is not legible, the gap element should be used to indicate where text has not not transcribed, because it could not be. The unclear element described in section 11.5.1 Damage, Illegibility, and Supplied Text may be used to indicate areas of text which cannot be read with confidence. See further section 11.3.7 Text Omitted from or Supplied in the Transcription and section 11.5.1 Damage, Illegibility, and Supplied Text.
11.3.5 SubstitutionsTEI: Substitutions¶
Substitution of one word or phrase for another is perhaps the most common of all phenomena requiring special treatment in transcription of primary textual sources. It may be simply one word overwriting another, or deletion of one word and its replacement by another written above it by the same hand at the one time; the deletion and replacement may be done by different hands at different times; there may be a long chain of substitutions on the one stretch of text, with uncertainty as to the order of substitution and as to which of many possible readings should be preferred.
- subst (substitution) 追加と削除が一連の調整と考えられる場合,そのひとつ以上の追加部分や削 除部分をまとめる.
<delSpan rend="verticalStrike" spanTo="#delend02"/>
Tis moonlight <subst>
<del>upon</del>
<add>over</add>
</subst> Oman's sky
</l>
<l>Her isles of pearl look lovelily<anchor xml:id="delend02"/>
</l>
with <subst>
<del seq="1">this</del>
<del seq="2">
<add seq="1">such
a</add>
</del>
<add seq="2">a</add>
</subst> system, to appreciate its
advantages.
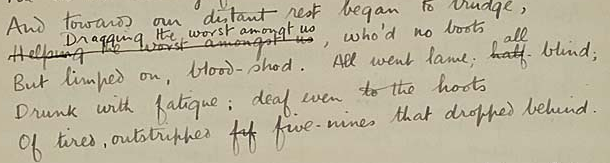
<l>
<subst>
<del>Helping the worst amongst us</del>
<add>Dragging the
worst amongt us</add>
</subst>, who'd no boots
</l>
<l>But limped on, blood-shod. All went lame;
<subst>
<del status="shortEnd">half-</del>
<add>all</add>
</subst> blind;</l>
<l>Drunk with fatigue ; deaf even to the hoots</l>
<l>Of tired, outstripped <del>fif</del> five-nines that dropped behind.</l>
- the false start fif in the last line is simply marked as a deletion;
- the other two authorial corrections are marked as substitutions, each combining a deletion and an addition.
- the authorial slip (amongt for amongst) is retained without comment.
<app>
<rdg varSeq="1">
<del>this</del>
</rdg>
<rdg varSeq="2">
<del>
<add>such a</add>
</del>
</rdg>
<rdg varSeq="3">
<add>a</add>
</rdg>
</app>
system, to appreciate its advantages.
11.3.6 Cancellation of Deletions and Other MarkingsTEI: Cancellation of Deletions and Other Markings¶
- restore 編集者や著者による指示を覆し,以前の状態のテキストを復元することを示 す.
This element bears the same attributes as the other transcriptional elements. These may be used to supply further information such as the hand in which the restoration is carried out, the type of restoration, and the person responsible for identifying the restoration as such, in the same way as elsewhere.
<restore hand="#dhl" type="marginalStetNote">
<del>my</del>
</restore>
body
Another feature commonly encountered in manuscripts is the use of circles, lines, or arrows to indicate transposition of material from one point in the text to another. No specific markup for this phenomenon is proposed at this time. Such cases are most simply encoded as additions at the point of insertion and deletions at the point of encirclement or other marking.
11.3.7 Text Omitted from or Supplied in the TranscriptionTEI: Text Omitted from or Supplied in the Transcription¶
- gap (gap) TEIヘダーにある編集上の理由,または当該資料が判読できない・聞こえな
いことを理由に,転記の際に省略された部分の場所を示す.
reason 省略の理由を示す.例えば, 見本, 聞こえない, 無関係, 取り消し, 取り消しがありかつ判読できない,など. hand 特定可能な筆致による熟慮した削除の場合,転記の際にその筆致を示す. agent 損傷が原因のテキスト省略の場合,特定可能であれば当該損傷を分類する. - surplus (Texte superflu) marks text present in the source which the editor believes to
be superfluous or redundant.
reason indicates the grounds for believing this text to be superfluous. - supplied
転記者や編集者にひょって付加されたテキストを示す.例えば,元のテキス
トが物理的損傷や欠損から判読できない場合などに付加されるもの.
reason 該テキストが付加された理由を示す.
reason="cancelled"
hand="#mb"
quantity="10"
unit="cm"/>—and
here is one of them...
As noted above, the gap element should only be used where text has not been transcribed. If partially legible text has been transcribed, one of the elements damage and unclear should be used instead (these elements are described in section 11.5.1 Damage, Illegibility, and Supplied Text); if the text is legible and has been transcribed, but the editor wishes to indicate that they regard it is superfluous or redundant, then the element surplus may be used in preference to the core element sic used to indicate text regarded as erroneous.
- mark this as an erroneous form
- additionally supply a corrected form
- indicate that the erroneous form contains surplus characters which the editor wishes to suppress
<surplus reason="interpolated">a tradimento</surplus>
</l>
<l n="5">sì com' l'uccellator prende l'uccello</l>
<gap/>
<l n="43">e lettere dintorno che diriano
<surplus reason="interpolated">in questa guisa</surplus>
</l>
<l n="44">Più v'amo, dëa, che non faccio Deo</l>
am dr Sr yr <supplied reason="illegible" resp="#msm" source="#Ry2">very humble Servt</supplied> Sydney Smith
11.4 Hands and ResponsibilityTEI: Hands and Responsibility¶
This section discusses in more detail the representation of aspects of responsibility perceived or to be recorded for the writing of a primary source. These include points at which one scribe takes over from another, or at which ink, pen, or other characteristics of the writing change. A discussion of the usage of the hand, resp, and cert attributes is also included.
11.4.1 Document HandsTEI: Document Hands¶
For many text-critical purposes it is important to signal the person responsible (the hand) for the writing of a whole document, a stretch of text within a document, or a particular feature within the document. A hand, as the name suggests, need not necessarily be identified with a particular known (or unknown) scribe or author; it may simply indicate a particular combination of writing features recognized within one or more documents. The examples given above of the use of the hand attribute with coding of additions and deletions illustrate this.
- handNote 手書き資料中にある特定のスタイルまたは筆致を示す.
A handNote element, with an identifier given by its xml:id attribute, may appear in either of two places in the TEI Header, depending on which modules are included in a schema. When the transcr module defined by the present chapter is used, the element handNotes is available, within the profileDesc element of the Header, to hold one or more handNote elements. When the msdescription module defined in chapter 10 Manuscript Description is included, the handDesc element described in 10.7.2 Writing, Decoration, and Other Notations also becomes available as part of a structured manuscript description. The encoder may choose to place handNote elements identifying individual hands in either location without affecting their accessibility since the element is always addressed by means of its xml:id attribute. The handDesc element may be more appropriate when a full cataloguing of each manuscript is required; the handNotes element if only a brief characterization of each hand is needed. It is also possible to use the two elements together if, for example, the handDesc element contains a single summary describing all the hands discursively, while the handNotes element gives specific details of each. The choice will depend on individual encoders' priorities.
- handShift/ テキストにおける新しい筆致の始まり,または筆写者の仕事の開始を示す.
- att.handFeatures
手書き資料の筆致に関する情報を表す情報を示す.
scribe 当該筆致に対応すると十分に信じられる筆写者の一般的な名前または識 別子を示す. script 当該筆致で使用されている特定の筆体や書記スタイルの特徴を示す.例 えば,secretary(書記官スタイル), copperplate(銅板スタイル), Chancery(公文書スタイル), Italian(イタリアスタイル)など. medium インクの種類や色合い,例えば,茶色 や,筆記具の種類,例えば,鉛筆など. scope 当該筆致が,当該手書き資料中で,どの程度出現しているかを示す.
A single hand may employ different writing styles and inks within a document, or may change character. For example, the writing style might shift from ‘anglicana’ to ‘secretary’, or the ink from blue to brown, or the character of the hand may change. Simple changes of this kind may be indicated by assigning a new value to the appropriate attribute within the handShift element. It is for the encoder to decide whether a change in these properties of the writing style is so marked as to require treatment as a distinct hand.
Where such a change is to be identified, the new attribute is used to indicate the hand applicable to the material following the handShift. This will ordinarily, but not necessarily, be the order in which the material was originally written.
As might be expected, one hand may employ different renditions within the one writing style, for example medieval scribes often indicate a structural division by emboldening all the words within a line. These should be indicated by use of the rend attribute on an element, in the same manner as underlining, emboldening, font shifts, etc. are represented in transcription of a printed text, rather than by introducing a new handShift element.
<handShift medium="greenish-ink"/>
<l>And if the cattes skynne be slyk <handShift medium="black-ink"/> and gaye</l>
<handNote xml:id="h1" script="copperplate" medium="brown-ink">Carefully written with regular descenders</handNote>
<handNote xml:id="h2" script="print" medium="pencil">Unschooled scrawl</handNote>
</handNotes>
may be once more introduced and Established in this
Parish according to the Rules and Ceremonies of the
Church of England and as under a good Consciencious
and sober Curate there would and ought to be
<handShift new="#h2" resp="#das"/>
and for that purpose the parishioners pray
11.4.2 Hand, Responsibility, and Certainty AttributesTEI: Hand, Responsibility, and Certainty Attributes¶
<choice>
<sic>One</sic>
<corr resp="#FB">one</corr>
</choice> must have
lived ...
<!-- elsewhere -->
<respStmt xml:id="FB">
<resp>editorial changes</resp>
<name>Fredson Bowers</name>
</respStmt>
<respStmt xml:id="WJ">
<resp>authorial changes</resp>
<name>William James</name>
</respStmt>
The resp attribute, by contrast, indicate the person responsible for deciding to apply the element carrying it to this part of the text, and hence has a slightly different interpretation. In the case of the add element, for example, the resp attribute will indicate the responsibility for identifying that the addition is indeed an addition, and also (if the hand attribute is supplied) to which hand it should be attributed. In this case, Bowers is credited with identifying the hand as that of William James. In the case of the corr element, the resp attribute indicates who is responsible for supplying the intellectual content of the correction reported in the transcription: here, Bowers' correction of ‘One’ to ‘one’. In the case of a deletion, the resp attribute will similarly indicate who bears responsibility for identifying or categorising the deletion itself, while other attributes (hand most obviously) attribute responsibility for the deletion itself.
In cases where both the resp and cert attributes are defined for a particular element, the two attributes refer to the same aspect of the markup. The one indicates who is intellectually responsible for some item of information, the other indicates the degree of confidence in the information. Thus, for a correction, the resp attribute signifies the person responsible for supplying the correction, while the cert attribute signifies the degree of editorial confidence felt in that correction. For the expansion of an abbreviation, the resp attribute signifies the person responsible for supplying the expansion and the cert attribute signifies the degree of editorial confidence felt in the expansion.
This close definition of the use of the resp and cert attributes with each element is intended to provide for the most frequent circumstances in which encoders might wish to make unambiguous statements regarding the responsibility for and certainty of aspects of their encoding. The resp and cert attributes, as so defined, give a convenient mechanism for this. However, there will be cases where it is desired to state responsibility for and certainty concerning other aspects of the encoding. For example, one may wish in the case of an apparent addition to state the responsibility for the use of the add element, rather than the responsibility for identifying the hand of the addition. It may also be that one editor may make an electronic transcription of another editor's printed transcription of a manuscript text — here, one will wish to assign layers of responsibility, so as to allow the reader to determine exactly what in the final transcription was the responsibility of each editor. In these complex cases of divided editorial responsibility for and certainty concerning the content, attributes, and application of a particular element, the more general mechanisms for representing certainty and responsibility described in chapter 21 Certainty, Precision, and Responsibility should be used.
<sic>wight</sic>
<corr resp="#ETD" cert="medium">wright</corr>
</choice>
<corr xml:id="c117">wright</corr>
<sic>wight</sic>
</choice>
<certainty target="#c117" locus="value" degree="0.7"/>
<respons target="#c117" locus="value" resp="#ETD"/>
The above discussion supposes that in each case an encoder is able to specify exactly what it is that one wishes to state responsibility for and certainty about. Situations may arise when an encoder wishes to make a statement concerning certainty or responsibility but is unable or unwilling to specify so precisely the domain of the certainty or responsibility. In these cases, the note element may be used with the type attribute set to ‘cert’ or ‘resp’ and the content of the note giving a prose description of the state of affairs.
11.5 Damage and ConjectureTEI: Damage and Conjecture¶
The carrier medium of a primary source may often sustain physical damage which makes parts of it hard or impossible to read. In this section we discuss elements which may be used to represent such situations and give recommendations about how these should be used in conjunction with the other related elements introduced previously in this chapter.
11.5.1 Damage, Illegibility, and Supplied TextTEI: Damage, Illegibility, and Supplied Text¶
- damage 当該文献におけるテキストの損傷部分を示す. 当該現存資料におけるテキストの損傷部分を示す.
- damageSpan/ (damaged span of text) 読める程度の損傷がある,一連のテキストの始点を示す.
- att.damaged 読みに影響を与える物理的損傷の性格を示す属性を示す.
hand 当該損傷部分の書き手が特定できる場合,それを示す. 当該損傷部分の書き手が特定できる場合,それを示す. agent 当該損傷の原因の分類を示す. 当該損傷の原因の分類を示す. degree 当該損傷部分の程度を示す.要素damageの属性 degreeは,当該損傷部分のテキストが確認できる場合にの み使用されるべきである.他の資料から補われたテキストの場合には, 要素suppliedで示されるべきである. 当該損傷部分の程度を示す.要素damageの属性 degreeは,当該損傷部分のテキストが確認できる場合にの み使用されるべきである.他の資料から補われたテキストの場合には, 要素suppliedで示されるべきである. group 各損傷部分に,物理的状況を示す,任意の数値を付与する. 各損傷部分に,物理的状況を示す,任意の数値を付与する.
- att.dimensions 物理的対象の大きさを表す属性を示す.
extent indicates the size of the object concerned using a project-specific vocabulary combining quantity and units in a single string of words. unit 当該大きさの単位を示す. quantity 当該単位の大きさを示す. - att.ranging provides attributes for describing numerical ranges.
min where the measurement summarizes more than one observation or a range, supplies the minimum value observed. max where the measurement summarizes more than one observation or a range, supplies the maximum value observed. atLeast gives a minimum estimated value for the approximate measurement. atMost gives a maximum estimated value for the approximate measurement.
- att.spanning
テキスト幅の範囲を内容としてではなく参照機能を使って示す要素に付与さ
れる属性を示す.
spanTo 当該要素が示す範囲の終点を示す.
The following examples all refer to the recto of folio 5 of the unique manuscript of the Elder Edda. Here, the manuscript of Vóluspá has been damaged through irregular rubbing so that letters in various places are obscured and in some cases cannot be read at all.
<!-- ... -->
<pb n="5r"/>
<damageSpan agent="rubbing" extent="whole leaf" spanTo="#damageEnd"/>
</p>
<p> .... </p>
<p> ....
<pb n="5v" xml:id="damageEnd"/>
</p>
<l>Moves <damage agent="water" group="1">on: nor all your</damage> Piety nor Wit</l>
<l>
<damageSpan agent="water" group="1" spanTo="#washOut"/>Shall lure it back to cancel half a Line,
</l>
<l>Nor all your Tears wash <anchor xml:id="washOut"/> out a Word of it</l>
A more general solution to this problem is provided by the join element discussed in 16.7 Aggregation which may be used to link together arbitrary elements of any kind in the transcription. Where, as here, several phenomena of illegibility and conjecture all result from the one cause, an area of damage to the text — rubbing at various points — which is not continuous in the text, affecting it at irregular points, the join element may be used to indicate which tagged features are part of the same physical phenomenon.
<unclear>aga</unclear>
</damage> yndisniota
<supplied source="#msm">aga</supplied>
</damage> yndisniota
neþan <gap
reason="illegible"
agent="rubbing"
quantity="4"
unit="letter"/>
<unclear>and the proof of this is</unclear>
<gap/>
<unclear>margin</unclear>
</damage>
11.5.2 Use of the <gap>, <del>, <damage>, <unclear>, and <supplied> Elements in CombinationTEI: Use of the gap, del, damage, unclear, and supplied Elements in Combination¶
- where the text has been rendered completely illegible by deletion or damage and no text is supplied by the editor in place of what is lost: place an empty gap element at the point of deletion or damage. Use the reason attribute to state the cause (damage, deletion, etc.) of the loss of text.
- where the text has been rendered completely illegible by deletion or damage and text is supplied by the editor in place of what is lost: surround the text supplied at the point of deletion or damage with the supplied element. Use the reason attribute to state the cause (damage, deletion, etc.) of the loss of text leading to the need to supply the text.
- where the text has been rendered partly illegible by deletion or damage so that the text can be read but without perfect confidence: transcribe the text and surround it with the unclear element. Use the reason attribute to state the cause (damage, deletion, etc.) of the uncertainty in transcription and the cert attribute to indicate the confidence in the transcription.
- where there is deletion or damage but at least some of the text can be read with perfect confidence: transcribe the text and surround it with the del element (for deletion) or the damage element (for damage). Use appropriate attribute values to indicate the cause and type of deletion or damage. Observe that the degree attribute on the damage element permits the encoding to show that a letter, word, or phrase is not perfectly preserved, though it may be read with confidence.
- where there is an area of deletion or damage and parts of the text within that area can be read with perfect confidence, other parts with less confidence, other parts not at all: in transcription, surround the whole area with the del element (for deletion; or the delSpan element where it crosses a structural boundary); or the damage element (for damage). Text within the damaged area which can be read with perfect confidence needs no further tagging. Text within the damaged area which cannot be read with perfect confidence may be surrounded with the unclear element. Places within the damaged area where the text has been rendered completely illegible and no text is supplied by the editor may be marked with the gap element. For each element, one may use appropriate attribute values to indicate the cause and type of deletion or damage and the certainty of the reading.
- if one add element (with identifier ADD1)
contains another (with identifier ADD2), then
the addition ADD1 was first
made to the text, and later a second addition (ADD2) was
made within that added text:
This is the text
<add xml:id="ADD1">with some added
<add xml:id="ADD2">(interlinear!)</add>
material</add>
as written. - if one del element contains another, and the
seq attribute does not indicate otherwise, it should be
assumed that the inner
deletion was made before the enclosing one. In the following example,
the word redundant was deleted before a second
second deletion removed the entire passage:
<del>This sentence contains
some <del>redundant</del> unnecessary
verbiage.</del> - if a del element contains an add element, the normal
interpretation will be that an addition was made within a passage
which was later
deleted in its entirety:
<del>This sentence was deleted
<add>originally</add> from the text.</del> - if an add element contains a del element, the
normal interpretation will be that a
deletion was made from a passage which had earlier been added:
<add>This sentence was added
<del>eventually</del> to the text.</add>
11.6 Aspects of LayoutTEI: Aspects of Layout¶
Finally in this chapter we present elements which may be used to capture aspects of the layout of material on a page where this is considered important. Methods for recording page breaks, column breaks, and line breaks in the source are described in section 3.10 Reference Systems.
- » 11.6.2 Lines
- ホーム | 目次
11.6.1 SpaceTEI: Space¶
- space
元資料にある重要な空白の場所を示す.
resp (responsible party) 当該空白を特定し測った責任のある人物を示す.
As <space quantity="7" unit="char"/> han within her oratoryes
As <supplied reason="space" resp="#ETD" source="#Hg">preestes</supplied>
han within her oratoryes
- « 11.6.1 Space
- ホーム | 目次
11.6.2 LinesTEI: Lines¶
<del rend="strikethrough" hand="#dhl">my</del> body,
which is so dear to me
by law — hindered a man's proceedings who
<hi rend="underline">had obtained all the letters
to Mr Boyd</hi>
by law — hindered a man's proceedings who
<hi xml:id="cstart1" rend="underline">had obtained all
the letters to Mr Boyd</hi>
<!-- ... -->
<certainty target="#cstart1" locus="start" degree="0.70">
<desc>may begin with previous word</desc>
</certainty>
Where the area of text marked overlaps other areas of text, for example crossing a structural division, one of the spanning mechanisms mentioned above must be used; for example where the line is thought to mark a deletion, the delSpan element may be used. Where it is desired simply to record the marking of a span of text in circumstances where it is not possible to surround the text with a hi element, the span element may be used with the rend or type attribute indicating the style of line-marking.
More work needs to be done on clarifying the treatment of other textual features marked by lines which might so overlap or nest. For example, in many Middle English manuscripts (e.g. the Jesus and Digby verse collections), marginal sidebars may indicate metrical structure: couplets may be linked in pairs, with the pairs themselves linked into stanzas. Or, marginal sidebars may indicate emphasis, or may point out a region of text on which there is some annotation: in many manuscripts of Chaucer's Wife of Bath's Prologue lines 655–8 are marked with nesting parentheses against which the scribe has written nota.
At the lowest level, all such features could be captured by use of the note element, containing a prose description of the manuscript at this point, enhanced by a link to a visual representation (or facsimile) of the feature in question. It is not yet clear how best to mark up such phenomena so as to obtain more usefully structured encodings. For example, in the Chaucer example just cited, one may wish to record that the nota is written in the Hengwrt manuscript in the right margin against a single large left parenthesis bracketing the four lines, with two right parentheses in the right margin bracketing two overlapping pairs of lines: the first and third, the second and fourth. The note element allows us to record that the scribe wrote nota, but is not well-adapted to show that the nota points both at all four lines and at two pairs of lines within the four lines.
11.7 Headers, Footers, and Similar MatterTEI: Headers, Footers, and Similar Matter¶
- fw 版面の周りにある柱やノンブルを示す.
- running heads (whether repeated or changing on every page, or alternating pages)
- running footers
- page numbers
- catch-words
- other material repeated from page to page, which falls outside the stream of the text
<fw type="pageNum" place="top-right">29</fw>
<fw type="sig" place="bot-centre">E3</fw>
<fw type="catch" place="bot-right">TEMPLE</fw>
11.8 Other Primary Source Features not Covered in these GuidelinesTEI: Other Primary Source Features not Covered in these Guidelines¶
We repeat the advice given at the beginning of this chapter, that these recommendations are not intended to meet every transcriptional circumstance ever likely to be faced by any scholar. They are intended rather as a base to enable encoding of the most common phenomena found in the course of scholarly transcription of primary source materials. These guidelines particularly do not address the encoding of physical description of textual witnesses: the materials of the carrier, the medium of the inscribing implement, the organisation of the carrier materials themselves (as quiring, collation, etc.), authorial instructions or scribal markup, etc., except insofaras these are involved in the broader question of manuscript description, as addressed by the msdescription module described in chapter 10 Manuscript Description.
11.9 Module for Transcription of Primary SourcesTEI: Module for Transcription of Primary Sources¶
- モジュール transcr: 転記モジュール
↑ 目次 « 10 Manuscript Description » 12 Critical Apparatus