
20 Non-hierarchical Structures
目次
-
Conflict between the hierarchy established by the physical structure of a document (e.g., volume, page, column, line) and its rhetorical or linguistic structure (e.g., chapters, paragraphs, sentences, acts, scenes, etc.)
-
Conflict between a verse text's metrical structure (e.g., its arrangement in stanzas and metrical lines) and its rhetorical or linguistic structure (e.g., phrases, sentences, and, for plays, acts, scenes, and speeches).
-
Conflict between metrical, rhetorical, or linguistic structure and the representation of direct speech, especially if the quoted speech is interrupted by other elements (e.g., ‘What’, she asked, ‘was that all about’) or crosses metrical, rhetorical, or linguistic boundaries.
-
Conflict between different analytical views or descriptions of a text or document, e.g., markup intended to encode diplomatic information about a word's appearance in a manuscript with markup intended to describe its morphology or pronunciation.
Non-nesting information poses fundamental problems for any XML-based encoding scheme, and it must be stated at the outset that no current solution combines all the desirable attributes of formal simplicity, capacity to represent all occurring or imaginable kinds of structures, suitability for formal or mechanical validation. The representation of non-hierarchical information is thus necessarily a matter of trade-offs among various sets of advantages and disadvantages.
-
redundant encoding of information in multiple forms (discussed in 20.1 Multiple Encodings of the Same Information)
-
the use of empty elements to delimit the boundaries of a non-nesting structure (discussed in 20.2 Boundary Marking with Empty Elements)
-
the division of a logically single non-nesting element into segments that nest properly in their immediate hierarchical context but can also be reconstituted virtually across these hierarchical boundaries (discussed 20.3 Fragmentation and Reconstitution of Virtual Elements)
-
stand-off markup: the annotation of information by pointing at it, rather than by placing XML tags within it (discussed in 20.4 Stand-off Markup)
Scorn not the sonnet:
The second example is the third stanza from the fourth section of Robert Pinsky'sScorn not the sonnet; critic, you have frowned,Mindless of its just honours; with this keyShakespeare unlocked his heart; the melodyOf this small lute gave ease to Petrarch's wound.
Essay on Psychiatrists:
These two texts can be analysed in various ways. The first, which we might describe as the ‘Metrical View’, encodes the text according to its metrical features: line divisions (as here), stanzas or cantos in larger poems, and perhaps prosodic features like stress or syllable patterns, alliteration, or rhyme. A second view, which we might describe as the ‘Grammatical’, encodes linguistic and rhetorical features: phonemes, morphemes, words, phrases, clauses, and sentences. A third view, the ‘Dialogic’, might concentrate on narrative voice: distinguishing between the narrator and their interlocutors and identifying individual segments as direct quotations. In our examples, we will restrict ourselves to relatively simple conflicts: for the Metrical View we will encode only metrical lines and line groups; for the Grammatical View we will restrict ourselves to encoding sentences; and for the Dialogic View, we only will distinguish direct quotation from other narration.Catholic woman of twenty-seven with five childrenAnd a first-rate body—pointed her fingerat the back of one certain man and asked me,"Is that guy a psychiatrist?" and by god he was! "Yes,"She said, "He looks like a psychiatrist."Grown quiet, I looked at his pink back, and thought.
20.1 Multiple Encodings of the Same InformationTEI: Multiple Encodings of the Same Information¶
Conceptually, the simplest method of disentangling two (or more) conflicting hierarchical views of the same information is to encode it twice (or more), each time capturing a single view.
Scorn not the sonnetmight be encoded as follows, using the l element to encode each metrical line:
<l>Mindless of its just honours; with this key</l>
<l>Shakespeare unlocked his heart; the melody</l>
<l>Of this small lute gave ease to Petrarch's wound.</l>
<seg>Scorn not the sonnet;</seg>
<seg>critic, you have frowned, Mindless of its just honours;</seg>
<seg>with this key Shakespeare unlocked his heart;</seg>
<seg>the melody Of this small lute gave ease to Petrarch's wound.</seg>
</p>
<l>Catholic woman of twenty-seven with five children</l>
<l>And a first-rate body—pointed her finger</l>
<l>at the back of one certain man and asked me,</l>
<l>"Is that guy a psychiatrist?" and by god he was! "Yes,"</l>
<l>She said, "He <emph>looks</emph> like a psychiatrist."</l>
<l>Grown quiet, I looked at his pink back, and thought.</l>
</lg>
<seg>Catholic woman of twenty-seven with five children And a
first-rate body—pointed her finger at the back of one certain man and
asked me, "Is that guy a psychiatrist?" and by god he was!</seg>
</p>
<p>
<seg>"Yes," She said, "He <emph>looks</emph> like a
psychiatrist."</seg>
</p>
<p>
<seg>Grown quiet, I looked at his pink back, and thought.</seg>
</p>
body—pointed her finger at the back of one certain man and asked me,
<said>Is that guy a psychiatrist?</said> and by god he was!
<said>Yes,</said> She said, <said>He <emph>looks</emph> like a
psychiatrist.</said> Grown quiet, I looked at his pink back, and
thought.</ab>
This method is TEI Conformant. Its advantages are that each way of looking at the information is explicitly represented in the data and that the individual views are simple to process. The disadvantages are that the method requires the maintenance of multiple copies of identical textual content (an invitation to inconsistency) and that there is no explicit indication that the various views, which might be in separate files, are related to each other: it might prove difficult to combine the views or access information from one view while processing the file that contains the encoding of another.75
20.2 Boundary Marking with Empty ElementsTEI: Boundary Marking with Empty Elements¶
A second method for accommodating non-hierarchical objects in an XML document involves marking the start and end points of the non-nesting material. This prevents textual features that fall outside the privileged hierarchy from invalidating the document while identifying their beginnings and ends for further processing. The disadvantage of this method is that no single XML element represents the non-nesting material and, as a result, processing with XML technologies is significantly more difficult.
The empty elements used at each end are called segment-boundary elements or segment-boundary delimiters. There are several variations on this method of encoding.
<seg>
<lb n="1"/>Scorn not the sonnet;</seg>; <seg>critic, you have
frowned, <lb n="2"/>Mindless of its just honours;</seg>
<seg>with this
key <lb n="3"/>Shakespeare unlocked his heart;</seg>
<seg>the melody
<lb n="4"/>Of this small lute gave ease to Petrarch's
wound.</seg>
</p>
The use of these elements is by definition TEI Conformant. Care should be taken, however, that the meaning of the milestone elements is preserved: semantically, for example, lb is used to mark the start of a new (typographical) line. While in much modern poetry, typographical and metrical line divisions correspond, lb does not itself make a metrical claim: in encoding verse from sources, such as Old English manuscripts, where physical line breaks are not used to indicate metrical lineation, the correspondence would break down entirely.
<anchor subtype="sentenceStart" type="delimiter"/>
Scorn not the sonnet;
<anchor subtype="sentenceEnd" type="delimiter"/>
<anchor subtype="sentenceStart" type="delimiter"/> critic, you have frowned,
</l>
<l>Mindless of its just honours; <anchor subtype="sentenceEnd" type="delimiter"/>
<anchor subtype="sentenceStart" type="delimiter"/> with this key</l>
<l>Shakespeare unlocked his heart; <anchor subtype="sentenceEnd" type="delimiter"/>
<anchor subtype="sentenceStart" type="delimiter"/> the melody</l>
<l>Of this small lute gave ease to Petrarch's wound. <anchor subtype="sentenceEnd" type="delimiter"/>
</l>
This method is TEI Conformant.
<n:sentenceBoundaryStart/>Scorn not the sonnet;
<n:sentenceBoundaryEnd/>
<n:sentenceBoundaryStart/>critic, you have frowned,
</l>
<l>Mindless of its just honours; <n:sentenceBoundaryEnd/>
<n:sentenceBoundaryStart/>with this key</l>
<l>Shakespeare unlocked his heart; <n:sentenceBoundaryEnd/>
<n:sentenceBoundaryStart/>the melody</l>
<l>Of this small lute gave ease to Petrarch's wound. <n:sentenceBoundaryEnd/>
</l>
If the custom elements can be replaced by TEI elements and attributes without loss of information, this method is TEI Conformable (see 23.3 Conformance); if the custom elements introduce information or distinctions that cannot be captured using standard TEI elements, the method is an extension.
<l>
<seg>Scorn not the sonnet;</seg>
<hr:s sID="s02"/>critic, you have frowned, </l>
<l>Mindless of its just honours; <hr:s eID="s02"/>
<hr:s sID="s03"/>with this key </l>
<l>Shakespeare unlocked his heart; <hr:s eID="s03"/>
<hr:s sID="s04"/>the melody </l>
<l>Of this small lute gave ease to Petrarch's wound. <hr:s eID="s04"/>
</l>
</lg>
- The method is TEI Conformable if the modified elements are placed in a distinct, non-TEI-namespace (see 23.3.4 Use of the TEI Namespace), and if the modified elements and attributes can be mapped without loss of information to existing TEI markup structures such as milestone or anchor elements automatically (see 23.3 Conformance).
- The method represents an Extension if the modified elements are placed in a distinct, non-TEI namespace, but contain information or distinctions that cannot be algorithmically translated to existing TEI elements without loss of information (see 23.3 Conformance).
- The method is non-conformant — and indeed strongly deprecated — if the modified elements and attributes are not placed in a distinct, non-TEI namespace (see 23.3.3 Conformance to the TEI Abstract Model).
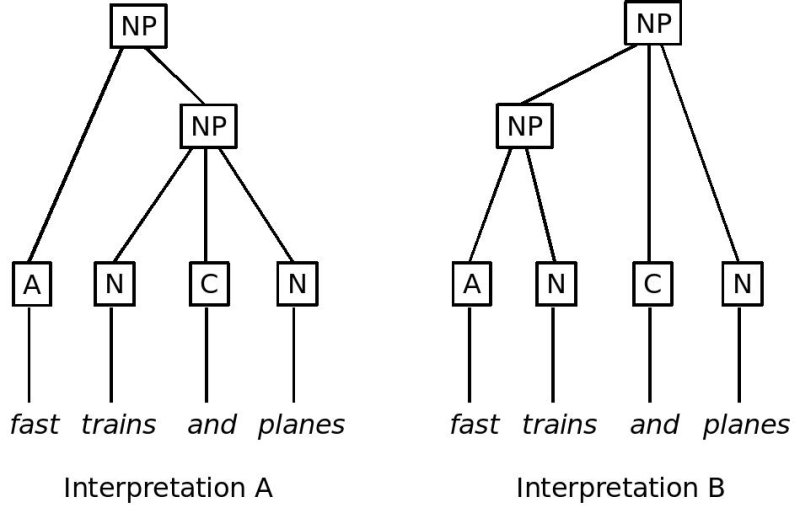
<anchor type="delimiter" subtype="NPstart" xml:id="NPInterpretationB"/>
<w function="A">Fast</w>
<anchor type="delimiter" subtype="NPstart" xml:id="NPInterpretationA"/>
<w function="N">trains</w>
<anchor type="delimiter" subtype="NPend" corresp="#NPInterpretationB"/>
<w function="C">and</w>
<w function="N">planes</w>
<anchor type="delimiter" subtype="NPend" corresp="#NPInterpretationA"/>
</phr>
In this encoding, the first interpretation, in which fast modifies the NP trains and planes, the NP trains and planes is opened using an anchor tag with the xml:id value NPInterpretationA and closed with an anchor with the same value on corresp; in the second interpretation, in which fast forms a NP with trains, the NP fast cars is opened using an anchor tag with the xml:id value NPInterpretationB and closed with an anchor tag that has the same value on corresp.
Despite their advantages, segment boundary delimiters incur the disadvantage of cumbersome processing: since the elements of the analysis (e.g., the sentences in the poems, or phrases in the above example) are not uniformly represented by nodes in the document tree, they must be reconstituted by software in an ad hoc fashion, which is likely to be difficult and may be error prone.
Most important for some encoders, the method also disguises the relationship between the beginning and the ending of each logical element. This makes it impossible for standard validation software to provide the same kind of validation possible elsewhere in the encoding. When using grammar-based schema languages it is not possible to define a content model for the range limited by empty elements.76
20.3 Fragmentation and Reconstitution of Virtual ElementsTEI: Fragmentation and Reconstitution of Virtual Elements¶
A third method involves breaking what might be considered a single logical (but non-nesting) element into multiple smaller structural elements that fit within the dominant hierarchy but can be reconstituted virtually. For example, if a passage of direct discourse begins in the middle of one paragraph and continues for several more paragraphs, one could encode the passage as a series of said elements, each fitting within a p element. The resulting encoding is valid XML, but the text in each said element represents only a portion of the complete passage of direct discourse. For this reason these elements are sometimes called ‘partial elements’.
<l>Catholic woman of twenty-seven with five children</l>
<l>And a first-rate body—pointed her finger</l>
<l>at the back of one certain man and asked me,</l>
<l>
<said n="quotation1">Is that guy a psychiatrist?</said> and by god he was!
<said n="quotation2">Yes,</said>
</l>
<l>She said, <said n="quotation2">He <emph>looks</emph> like a
psychiatrist.</said>
</l>
<l>Grown quiet, I looked at his pink back, and thought.</l>
</lg>
<seg n="sentence1">Scorn not the sonnet;</seg>
<seg n="sentence2">critic, you have frowned,</seg>
</l>
<l>
<seg n="sentence2">Mindless of its just honours;</seg>
<seg n="sentence3">with this key</seg>
</l>
<l>
<seg n="sentence3">Shakespeare unlocked his heart;</seg>
<seg n="sentence4">the melody</seg>
</l>
<l>
<seg n="sentence4">Of this small lute gave ease to Petrarch's wound.</seg>
</l>
There are two main problems with this type of encoding. The
first is that it invariably means that the encoding will have
more elements claiming to represent a feature than there are
actual instances of that feature in the text. Thus, for
example, the passage from Scorn not the
sonnet
marks seven spans of text using seg,
even though there are only four linguistic sentences in the
passage.
The second problem is that it can be semantically misleading. Although they are tagged using the element for sentence, for example, very few of the textual features encoded using seg in this example represent actual linguistic sentences: with this key, for example, is a prepositional phrase, not a sentence; Of this small lute gave ease to Petrarch's wound is a string corresponding to no single grammatical category.
Taken together, these problems can make automatic analysis of the fragmented features difficult. An analysis that intended to count the number of sentences in Wordsworth's poem, for example, would arrive at an inflated figure if it understood the seg elements to represent complete rhetorical sentences; if it wanted to do an analysis of his syntax, it would not be able to assume that seg delimited linguistic sentences.
Scorn not the sonnetagain; this time the relationship between the parts of the fragmented sentences is indicated explicitly using the next and prev attributes described in 16.7 Aggregation.
<seg>Scorn not the sonnet;</seg>
<seg next="#s2b" xml:id="s2a">critic, you have frowned,</seg>
</l>
<l>
<seg prev="#s2a" xml:id="s2b">Mindless of its just honours;</seg>
<seg next="#s3b" xml:id="s3a">with this key</seg>
</l>
<l>
<seg prev="#s3a" xml:id="s3b">Shakespeare unlocked his heart;</seg>
<seg next="#s4b" xml:id="s4a">the melody</seg>
</l>
<l>
<seg prev="#s4a" xml:id="s4b">Of this small lute gave ease to Petrarch's wound.</seg>
</l>
<seg>Scorn not the sonnet;</seg>
<seg part="I">critic, you have frowned,</seg>
</l>
<l>
<seg part="F">Mindless of its just honours;</seg>
<seg part="I">with this key</seg>
</l>
<l>
<seg part="F">Shakespeare unlocked his heart;</seg>
<seg part="I">the melody</seg>
</l>
<l>
<seg part="F">Of this small lute gave ease to Petrarch's wound.</seg>
</l>
<l>
<seg part="I">Catholic woman of twenty-seven with five children</seg>
</l>
<l>
<seg part="M">And a first-rate body—pointed her finger</seg>
</l>
<l>
<seg part="M">at the back of one certain man and asked me,</seg>
</l>
<l>
<seg part="F">"<seg>Is that guy a psychiatrist?</seg>" and by god he was!</seg>
<seg part="I">"<seg part="I">Yes,</seg>"</seg>
</l>
<l>
<seg part="F">She said, "<seg part="F">He <emph>looks</emph> like a psychiatrist.</seg>"</seg>
</l>
<l>
<seg>Grown quiet, I looked at his pink back, and thought.</seg>
</l>
</lg>
<w xml:id="w01">Scorn</w>
<w xml:id="w02">not</w>
<w xml:id="w03">the</w>
<w xml:id="w04">sonnet</w>; <w xml:id="w05">critic</w>, <w xml:id="w06">you</w>
<w xml:id="w07">have</w>
<w xml:id="w08">frowned</w>,
</l>
<l>
<w xml:id="w09">Mindless</w>
<w xml:id="w10">of</w>
<w xml:id="w11">its</w>
<w xml:id="w12">just</w>
<w xml:id="w13">honours</w>; <w xml:id="w14">with</w>
<w xml:id="w15">this</w>
<w xml:id="w16">key</w>
</l>
<l>
<w xml:id="w17">Shakespeare</w>
<w xml:id="w18">unlocked</w>
<w xml:id="w19">his</w>
<w xml:id="w20">heart</w>; <w xml:id="w21">the</w>
<w xml:id="w22">melody</w>
</l>
<l>
<w xml:id="w23">Of</w>
<w xml:id="w24">this</w>
<w xml:id="w25">small</w>
<w xml:id="w26">lute</w>
<w xml:id="w27">gave</w>
<w xml:id="w28">ease</w>
<w xml:id="w29">to</w>
<w xml:id="w30">Petrarch's</w>
<w xml:id="w31">wound</w>.
</l>
<!-- Elsewhere in the document -->
<p>
<join result="s" scope="root" target="#w01 #w02 #w03 #w04"/>
<join
result="s"
scope="root"
target="#w05 #w06 #w07 #w08 #w09 #w10 #w11 #w12 #w13"/>
<join result="s" scope="root" target="#w14 #w15 #w16 #w17 #w18 #w19 #w20"/>
<join
result="s"
scope="root"
target="#w21 #w22 #w23 #w24 #w25 #w26 #w27 #w28 #w29 #w30 #w31"/>
</p>
This use of join is TEI Conformant.
The major advantage of fragmentation and virtual joins is that it allows all the hierarchies in the text to be handled explicitly: both the privileged one directly represented and the alternate hierarchy that has been split up and rejoined. The major disadvantages are that (like most of the other methods described here) it privileges one hierarchy over the others, requires special processing to reconstitute the elements of the other hierarchies, and, except in the case of join, can be semantically misleading.
20.4 Stand-off MarkupTEI: Stand-off Markup¶
<w xml:id="w001">Scorn</w>
<w xml:id="w002">not</w>
<w xml:id="w003">the</w>
<w xml:id="w004">sonnet</w>; <w xml:id="w005">critic</w>, <w xml:id="w006">you</w>
<w xml:id="w007">have</w>
<w xml:id="w008">frowned</w>,
</l>
<l>
<w xml:id="w009">Mindless</w>
<w xml:id="w010">of</w>
<w xml:id="w011">its</w>
<w xml:id="w012">just</w>
<w xml:id="w013">honours</w>; <w xml:id="w014">with</w>
<w xml:id="w015">this</w>
<w xml:id="w016">key</w>
</l>
<l>
<w xml:id="w017">Shakespeare</w>
<w xml:id="w018">unlocked</w>
<w xml:id="w019">his</w>
<w xml:id="w020">heart</w>; <w xml:id="w021">the</w>
<w xml:id="w022">melody</w>
</l>
<l>
<w xml:id="w023">Of</w>
<w xml:id="w024">this</w>
<w xml:id="w025">small</w>
<w xml:id="w026">lute</w>
<w xml:id="w027">gave</w>
<w xml:id="w028">ease</w>
<w xml:id="w029">to</w>
<w xml:id="w030">Petrarch's</w>
<w xml:id="w031">wound</w>.
</l>
<!-- elsewhere in the current document -->
<p xmlns:xi="http://www.w3.org/2001/XInclude">
<seg>
<xi:include xpointer="range(element(w001),element(w004))"/>
</seg>
<seg>
<xi:include xpointer="range(element(w005),element(w013))"/>
</seg>
<seg>
<xi:include xpointer="range(element(w014),element(w020))"/>
</seg>
<seg>
<xi:include xpointer="range(element(w021),element(w031))"/>
</seg>
</p>
This is very similar to the use of join discussed above. The main advantages of the stand-off method are that it is possible to specify attributes on the aggregate seg elements, and that there exists off-the-shelf software that will perform appropriate processing. Stand-off markup may be used even when the base text being annotated is plain text, i.e. does not have any XML encoding. In this case, the range of text to be marked up is indicated by character offsets (see 16.2.4 TEI XPointer Schemes, in particular 16.2.4.5 string-range(fragmentIdentifier, offset [, length])). Another distinction concerns the number of files which can serve as link targets. Often, one (dedicated) annotation is used as the link target of all the other annotations. It is also possible to freely interlink several layers.
It has been noted that stand-off markup has several advantages over embedded annotations. In particular, it is possible to produce annotations of a text even when the source document is read-only. Furthermore, annotation files can be distributed without distributing the source text. Further advantages mentioned in the literature are that discontinuous segments of text can be combined in a single annotation, that independent parallel coders can produce independent annotations, and that different annotation files can contain different layers of information. Lastly, it has also been noted that this approach is elegant.
But there are also several drawbacks. First, new stand-off annotated layers require a separate interpretation, and the layers — although separate — depend on each other. Moreover, although all of the information of the multiple hierarchies is included, the information may be difficult to access using generic methods.
Inasmuch as it uses elements not included in the TEI namespace, stand-off markup involves an extension of the TEI.
20.5 Non-XML-based ApproachesTEI: Non-XML-based Approaches¶
There exist many non-XML methods of encoding a text that either solve or do not suffer the problem of the inability to encode overlapping hierarchies. These include, but are not limited to, the following proposals.
- Applying the notion of concurrent markup to XML (Hilbert et al. (2005)). This reintroduces the CONCUR feature of SGML, which was omitted from the XML specification.
- Designing a form of document representation in which several trees share all or part of the same frontier, and in which each individual view of the document has the form of a tree (see Dekhtyar and Iacob (2005)).
- The ‘colored XML’ proposal (Jagadish et al. (2004)), which stores a body of information as a set of intertwined XML trees. This approach eliminates unnecessary redundancy and makes the database readily updatable, while allowing the user to exploit different hierarchical access paths.
- The MultiX proposal (Chatti et al. (2007)) , which represents documents as directed graphs. Because XML is used to represent the graph, the document is, at least in principle, manipulable with standard XML tools.
- The Just-In-Time-Trees proposal (Durusau and O'Donnell (2002)), which stores documents using XML, but processes the XML representation in non-standard ways and allows it to be mapped onto data structures that are different from those known from XML.
- The Layered Markup and Annotation Language (LMNL) proposal. This offers alternatives to the basic XML linear form as well as its data and processing models. It uses an alternative notation to XML and a data structure based on Core Range Algebra (Tennison and Piez (2002)).
- Markup Languages for Complex Documents (MLCD). This provides a notation (TexMECS) and a data structure (Goddag) as well as a draft constraint language for the representation of non-hierarchical structures; see Huitfeldt and Sperberg-McQueen (2001).
These approaches are based either on non-standard XML processing or data models, or not based on XML at all. Since TEI is currently based on XML they are not described any further in these Guidelines. Use of these methods with the TEI will certainly involve extensions; in most cases the documents will also be non-conformant.