9 Computer-mediated Communication
Indice
This chapter describes the TEI encoding mechanisms available for textual data that represents discourse from genres of computer-mediated communication (CMC). It is intended to provide the basic framework needed to encode CMC corpora.
TEI: General Considerations⚓︎9.1 General Considerations
While the term computer-mediated communication might be used broadly to describe all kinds of communications that are mediated by digital technologies (such as text on web pages, written exchanges in chats and forums, interactions with artificial intelligence systems, the spoken conversations in internet video meetings), for the purposes of these Guidelines we use the term to apply to forms of communication that share the following features:
- they are dialogic;
- they are organized as interactional sequences so that each communicative move may determine the context for subsequent moves (typically taken by another interlocutor) and may react to the context created by a prior move;
- they are created and displayed using computer technology or human-machine interfaces such as keyboard, mouse, speech-to-text conversion software, monitor or screen and transmitted over a computer network (typically the internet).
Such communications may be expressed as posts (cf. 9.3.1 CMC Posts), utterances, onscreen activities, or bodily activities exerted by a virtual avatar.
The following kinds of platforms support CMC:
- chats, messengers, or online forums;
- social media platforms and applications;
- the communication functions of collaborative platforms and projects (e.g. an online learning environment, or a ‘talk’ page);
- 3D virtual world environments;
- other interactive services supported by the internet.
CMC supports multimodal expression combining text, images, sound. Whereas early CMC systems (e.g. Internet Relay Chat, ‘IRC’ for short, the Usenet ‘newsgroups’, or even the Unix talk system) were completely ASCII-based, most CMC applications now permit combining media formats (e.g. written or spoken language with graphic icons and images) and mixing communication technologies on one platform (e.g. combined use of an audio connection, a chat system, and a 3D interface in which users control a virtual avatar as in many multiplayer online computer games or in virtual worlds).
TEI: Basic Units of CMC⚓︎9.2 Basic Units of CMC
This section describes the encoding mechanisms for the basic units of CMC and for their combined use to encode CMC data.
We use the term basic CMC unit to refer to a communication produced by an interlocutor to initiate or contribute to an ongoing CMC interaction or joint CMC activity. Contributions to an ongoing interaction are produced to perform a move to develop the interactional sequence, for instance to respond in chats or forum discussions. Contributions to joint CMC activities may not all be directly interactional; some may be part of a collaborative project of the involved individuals. Such collaboration could involve editing activities in a shared text editor or whiteboard in parallel with an ongoing CMC interaction (chat, audio conversation, or audio-video conference) in the same CMC environment in which these editing activities are discussed by the participants.
Basic units of CMC can be described according to three criteria:
- the temporal properties of when these contributions are produced by their creators, transmitted via CMC systems, and made accessible for the recipients;
- the modality of the unit as a whole, whether verbal or nonverbal;
- for verbal units: whether the unit is expressed in the written or spoken mode.
A taxonomy of basic CMC units resulting from these criteria is given in the following figure.
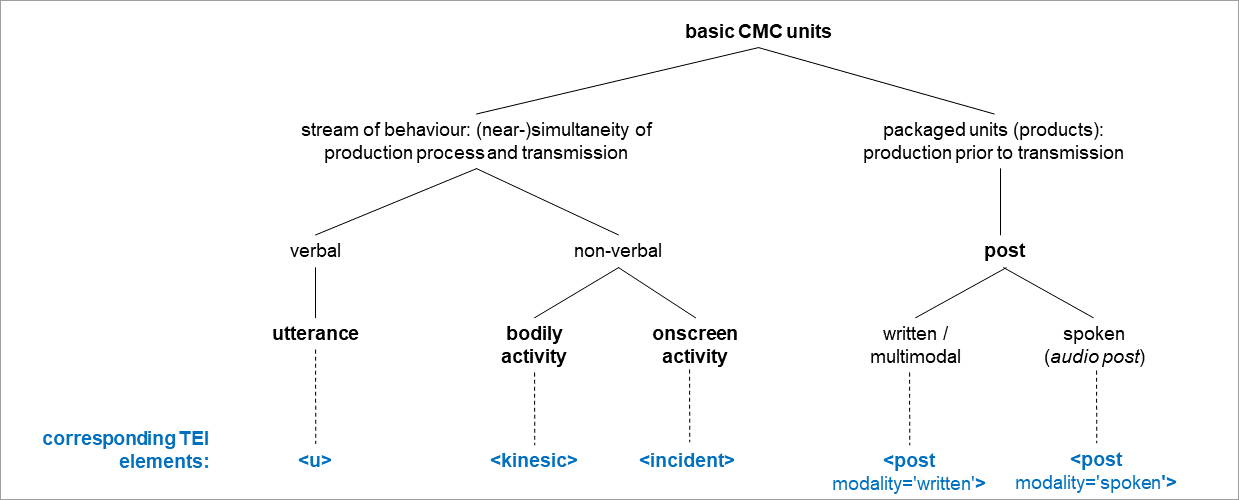
The most important distinction in the CMC taxonomy concerns the temporal nature of units exchanged via CMC technologies. The left part of the taxonomy describes units that are performed (by a producer) and perceived (by a recipient) as a continuous stream of behaviour. Units of this type can be performed as
- spoken utterances,
- i.e. stretches of speech which are produced to perform a speaker turn in a conversation,
- bodily activity,
- i.e. nonverbal behaviour (gesture, gaze) produced to perform a speaker turn, either performed by the real body of an interlocutor (e.g. in a video conference) or through the virtual avatar of an interlocutor in a 3D environment,
- onscreen activities,
- i.e. non-bodily expressions that are transmitted to the group of interacting or coworking participants, for instance the editing of content in a shared text editor which can be perceived by the other parties simultaneously (as may be the case in learning or collaboration environments).
The right part of the CMC taxonomy describes units in which the production, transmission, and perception of contributions to CMC interactions are organized in a strictly consecutive order: The content—verbal, nonverbal, or multimodal—of the contribution has to be produced before it can be transmitted through a network and made available on the computer monitor or mobile screen of any other party as a preserved and persistent unit. We term this type of unit a post. Posts occur in two different variants:
- as written or multimodal posts, which are produced with an editor form that is designed for the composition of stretches of written text. Most contemporary post-based CMC technologies provide features for the inclusion of graphic and audio-visual content (emoji graphics, images, videos) into posts and even to produce posts without verbal content (which then may consist only of emojis, an image, or a video file). Written and multimodal posts are the standard formats for user contributions in primarily text-based CMC genres and applications such as chat, SMS, WhatsApp, Instagram, Facebook, X (Twitter), online forums, or Wikipedia talk pages.
- as audio posts, which are produced using a recording function. In contrast to CMC units of the type utterance which are produced and transmitted simultaneously, audio posts first have to be recorded as a whole and are then transmitted, as audio files, via the internet; the availability of the recording is indicated in the screen protocol by a template-generated, visual post; the recipients can play the recording (repeatedly) by activating the play button displayed in the post on the screen. Examples of CMC applications that implement audio posts are WhatsApp or RocketChat.
Three of the four basic CMC units described above can be represented with models that are described elsewhere in the TEI Guidelines:
| CMC unit | Type of corpus data | TEI P5 element |
| spoken utterance | transcription of speech | u |
| bodily activity | textual description | kinesic |
| onscreen activity | textual description | incident |
The u, kinesic, and incident elements are not limited to CMC, but apply to encode textual transcriptions of spoken turns and CMC data about bodily activity and onscreen activity. The CMC unit post, which is specific to CMC, is introduced in 9.3.1 CMC Posts.
TEI: Encoding Unique to CMC⚓︎9.3 Encoding Unique to CMC
This section describes elements, attributes, and models which are unique to CMC and the TEI CMC module.
TEI: CMC Posts⚓︎9.3.1 CMC Posts
While the concept of a post is not unique to computer-mediated communication (ask anyone who has posted a ‘lost cat’ sign in the local market), this chapter concerns itself only with postings within a framework of a CMC system. Thus the element post is unique to the encoding of computer-mediated communication (CMC).
- post a written (or spoken) contribution to a CMC interaction which has been composed (or recorded) by its author in its entirety before being transmitted over a network (e.g., the internet) and made available on the monitor or screen of the other parties en bloc.
Posts occur in a broad range of written CMC genres, including (but not limited to) messages in chats and WhatsApp dialogues, tweets in X (Twitter) timelines, comments on Facebook pages, posts in forum threads, and comments or contributions to discussions on Wikipedia talk pages or in the comment sections of weblogs.
Posts can be either written or spoken:
- written or multimodal posts: In the majority of CMC technologies posts are composed as stretches of text using a keyboard or speech-to-text conversion software in an entry form on the screen. In many cases the technology allows authors to include or embed graphics (emojis or images), video files, and hyperlinks into their posts.
- spoken (audio posts): A growing number of CMC technologies, e.g. messenger software such as WhatsApp or RocketChat, allow for an alternative, spoken production of posts by providing a recording function which allows users to record a stretch of spoken language and transmit the resulting audio file to the other parties.
The element post may co-occur with u, kinesic, incident, or other existing TEI elements within a div, or directly within the body, and may contain headings, paragraphs, openers, closers, or salutations.
The post element is a member of several TEI attribute classes, including att.ascribed, att.canonical, att.datable, att.global, att.timed, and att.typed, and as such may take a variety of attributes.
TEI: Attributes Specific to CMC post⚓︎9.3.2 Attributes Specific to CMC <post>
- post a written (or spoken) contribution to a CMC interaction which has been composed (or
recorded) by its author in its entirety before being transmitted over a network (e.g.,
the internet) and made available on the monitor or screen of the other parties en
bloc.
modality written or spoken mode. I valori suggeriti includono: 1] written; 2] spoken (for audio (or audio-visual) posts) replyTo indicates to which previous post the current post replies or refers. - att.indentation provides attributes for describing the indentation of a textual element on the source
page or object.
indentLevel specifies the level of indentation of an item using a numeric value.
generatedBy="human" synch="#t005" who="#A06"
xml:id="cmc_post09">
<figure type="image" generatedBy="human">
<desc xml:lang="en">screenshot of the google search for hairdresser "Pasha's Haare'm"
with the average google rating (4,5 of 5 stars), the address, the phone number, and
the opening hours.</desc>
</figure>
</post>
The replyTo attribute is used to capture information drawn from the original metadata associated with a post that asserts to which previous post the current post is a response, or to which previous post it refers. This metadata is included by many, but not all, CMC environments, when the user executes a formal reply action (e.g., by clicking or tapping a reply button). This attribute should not be used to encode interpreted or inferred reply relations based on linguistic cues or discourse markers.
generatedBy="human" xml:id="cmc_post10" who="#u7"
replyTo="#cmc_post09" when-iso="2015-07-29T21:44">
<p>Es hat den Anschein, als wäre bei BER durchaus große Kompetenz am Bau, allerdings
nicht in Form von Handwerkern….</p>
<p>http://www.zeit.de/2015/29/imtech-flughafen-berlin-ber-verzoegerung/komplettansicht</p>
</post>
<post type="comment" modality="written"
generatedBy="human" xml:id="cmc_post11" who="#u8"
replyTo="#cmc_post10" when-iso="2015-07-30T19:11">
<p>Nein Nein, an den Handwerkern kann es rein strukturel nicht gelegen haben. Niemand
lässt seine Handwerker auf der Baustelle derart allein. Zudem gibt es höchstoffizielle
“Abnahmen” von Bauabschnitten/phasen. Welcher Mangel auch bestanden hatte, er hätte
Zeitnah auffallen müssen.</p>
<p>Uuups, für Imtek hab ich mal in einer Nachunternehmerfirma gearbeitet. Imtek is
offenbar ein universeler Bauträger, der alles baut.</p>
</post>
<post type="comment" modality="written"
generatedBy="human" xml:id="cmc_post12" who="#u8"
replyTo="#cmc_post11" when-iso="2015-07-30T19:26">
<p>Stahlkunstruktionen dacht ich mal, was die bauen—oder bauen lassen.</p>
<p>Das ist schon ein übles Ding. Die Ausschreibungenund Angebote sind unauffällig, aber
wenn Unregelmässigkeiten auftreten (im Bauverlauf) dann gibt es die saftigen
Rechnungen. Da steht dann der Bauherr da und fragt sich, wie er denn so schnell einen
fähigen Ersatz herbekommt. Und diese Frage erübrigt sich meist, weil der Markt der
Baufirmen das nicht hergibt — weil tendenziel 100 % Auslastung. (und noch schlimmer:
Absprachen) Was auch Folge des Marktdrucks gewesen war.</p>
</post>
In the CMC genre of wiki talk, users insert their contribution to a discussion by modifying the wiki page of the discussion—the talk page. Since there is no technical reply action available in wiki software, users apply textual indentation in the wiki code to indicate a reply to a previous message, and a threaded structure is formed by a series of such indentations. The attribute indentLevel records the level of indentation, that is the nesting depth of the current post in such a thread-like structure (as defined by its author and in relation to the standard level of non-indentation which should be encoded with an indentLevel of 0). It is used in wiki talk corpora but may also be used for other threaded genres, for example when HTML is used as a source.
<head>[[WP:AUTO]]</head>
<post indentLevel="0" modality="written"
when-iso="2006-09-07T03:09+00" who="#WU00010808" xml:id="cmc_post13">
<p> I would kindly request from Mr. Meyer to allow others to edit the [...]</p>
</post>
<post indentLevel="1" modality="written"
when-iso="2006-09-08T03:49+00" who="#WU00010804" xml:id="cmc_post14">
<p>I dont agree, this article is not about Dr. Meyer, [...]</p>
</post>
<post indentLevel="2" modality="written"
when-iso="2006-09-08T04:16+00" who="#WU00005520" xml:id="cmc_post15">
<p>Why don't you read the policy. [...]</p>
</post>
<post indentLevel="3" modality="written"
when-iso="2006-11-01T22:58+00" who="#WU00010815" xml:id="cmc_post16">
<p>Because the policy makes no sense, [...]</p>
</post>
</div>
TEI: Attributes for General CMC Encoding⚓︎9.3.3 Attributes for General CMC Encoding
The attribute generatedBy is also unique to CMC encoding. But unlike modality, replyTo, and indentLevel, generatedBy is available not only on the post element, but on any of its descendants as well.
- att.cmc (computer-mediated communication) provides attributes categorizing how the element
content was created in a CMC environment.
generatedBy (generated by) categorizes how the content of an element was generated in a CMC environment. I valori suggeriti includono: 1] human; 2] template; 3] system; 4] bot; 5] unspecified
The generatedBy attribute may indicate, for post or any of its descendants, how the content transcribed in an element was generated in a CMC environment. That is, whether the source text being transcribed was created by a human user, created by the CMC system at the request of a human user (e.g., when the user activates a template that generates the content, such as in a signature), generated by the CMC system (e.g. a status message or a timestamp), or generated by an automated process external to the CMC system itself. This attribute is optional; when it is not specified on a post element its value is presumed to be unspecified; when it is unspecified on any descendant of post its value is inherited from the immediately enclosing element. In turn, if generatedBy is not specified on that element it inherits the value from its immediately enclosing element, and so on up the document hierarchy until a post is reached; the post either has a generatedBy attribute specified or its presumed value is unspecified.
A list of suggested values for generatedBy follows:
- human
- when the content of the respective element was ‘naturally’ typed or spoken by a human user (cf. the chat posts in example haircut)
- template
- when the content of the respective element was generated after a human user activated a template for its insertion (often applicable to signed and time; e.g. see the signature in wiki talk in this example below)
- system
- when the content of the respective element was generated by the system, i.e. the CMC environment (see, e.g., the system message in an IRC chat in the this other example below)
- bot
- when the content of the respective element was generated by a bot, i.e. a non-human agent, typically one that is not part of the CMC environment itself
- unspecified
- when it is unspecified or unknown how the content of the respective element was generated (see, e.g. the retweet that forms the second post in this example below).
generatedBy="human" synch="#t003" who="#A02"
xml:id="cmc_post18" xml:lang="de"> Da kostet ein Haarschnitt 50 €
<figure type="emoji"
generatedBy="template">
<desc type="label" xml:lang="en">face screaming in fear</desc>
<desc type="unicode">U+1F631</desc>
</figure>
</post>
xml:id="cmc_post19" indentLevel="0" who="#u005" synch="#t005">
<p>I'm not sure that this is a proper criterium, or even what this means. What if we set
an explosion that breaks a comet into two pieces? What if we build a moon? Cheers,
</p>
<signed generatedBy="template"
rend="inline">
<ref target="/wiki/User:Greenodd">Greenodd</ref> (<ref target="/wiki/User_talk:Greenodd">talk</ref>) <time>01:00, 21
July 2011 (UTC)</time>
</signed>
</post>
generatedBy="human" synch="#tweetsbcrn18.t001"
xml:id="cmc_post_1043764753502486528" who="#u1" xml:lang="de">
<time generatedBy="system"> 12:31 </time> Heute mit super Unterstützung, wir grunzen,
wenn die Zeit vorbei ist. <ref type="hashtag"
target="https://twitter.com/hashtag/bcrn18?src=hash">#bcrn18</ref>
<ref type="hashtag"
target="https://twitter.com/hashtag/wikidach?src=hash">#wikidach</ref> PS: Die beiden brauchen noch Namen. Hinweise dazu am Empfang abgeben!
<ref type="twitter-account"
target="https://twitter.com/AndreLo79">@AndreLo79</ref>
<figure type="image">
<graphic url="https://pbs.twimg.com/media/DnwygdSW4AAoTUn.jpg:large"/>
</figure>
</post>
<post modality="written"
generatedBy="unspecified" type="tweet" who="#u1"
synch="#tweetsbcrn18.t002" xml:id="cmc_post_1043769240136880128">
<ptr type="retweet"
target="#cmc_post_1043767827927388160"/>
</post>
<post modality="written"
generatedBy="human" type="tweet" who="#u3"
synch="#tweetsbcrn18.t002" xml:lang="de"
xml:id="cmc_post_1043767827927388160">
<time generatedBy="system"> 12:43 </time>
<figure type="image" generatedBy="human">
<graphic url="https://pbs.twimg.com/media/Dnw1TRNXgAAKqlK.jpg:large"/>
</figure>
</post>
who="#SYSTEM" rend="color:navy">
<p>
<name type="nickname" ref="#A07">Interseb</name> betritt den Raum.</p>
</post>
TEI: CMC Macrostructure⚓︎9.4 CMC Macrostructure
In many CMC genres, posts may occur in a variety of ways: e.g. in a sequence or in threads, or grouped in some other way. For example, in chat communication such as WhatsApp, posts are part of ‘a chat’ of one user with another user or among a group of users. When an entire chat is saved, typically a ‘logfile’ of the chat is obtained from the CMC system and downloaded. Similarly, Wikipedia discussions occur on a talk page, which ultimately is a web page containing the user posts, sub-structured in threads. Likewise, YouTube comments occur on a webpage containing the YouTube video along with comment posts and posts replying to those comments displayed below the video. The video serves as a prompt for the whole discussion. In forum discussions, the prompt may be a news item, and in Wikipedia, an article may be viewed as the prompt for the discussion on the talk page associated with that article.
TEI: Macrostructure of CMC Collections and Documents⚓︎9.4.1 Macrostructure of CMC Collections and Documents
- The corpus level
-
The level of a corpus or collection of CMC texts of a particular genre, generally obtained from a particular CMC platform, sometimes even from several platforms. This level may be represented by either a TEI element or a teiCorpus element. The teiHeader of the corpus (i.e., the teiHeader that is a child of the outermost TEI or teiCorpus) will contain metadata in its sourceDesc about the CMC platform(s). Metadata about the project responsible for collecting the data and building the corpus, if applicable, should be recorded as well.
- The document level
-
A set of posts collected (or sampled) by a researcher for analysis. The posts of the document will often map directly to the set of posts grouped on an existing web page, thread, or document within a CMC environment. Within the CMC environment the document as such is often created by a particular user, thereby initiating the communication which other users may read, and to which some other users might contribute. This level will naturally be represented by the TEI element. The teiCorpus (or TEI) element that represents the corpus will contain one or more TEI elements as usual.
In the teiHeader of a document level TEI, the sourceDesc will contain metadata about the CMC document such as a title, its author or owner, its URL, the date of its creation, the date of the last change made to it, and other metadata that are available and to be recorded such as one or more categories associated with the document.
The document sometimes contains, or is associated with, a prompt such as a video or a news item, either provided by the initiating user herself or located elsewhere and referenced at the beginning of the document. In such cases, the teiHeader of the document should also contain metadata about this prompt.
- The post level
-
The level of the individual post is naturally represented by the post element; its encoding is further described in section 9.3.1 CMC Posts. A TEI element will contain a number of post elements, which can be grouped or ordered in div elements representing sequences or threads (section 9.4.2 Sequences, Sections, Threads) if appropriate.
<!-- a corpus, collection or dataset of CMC documents -->
<teiHeader>
<!-- metadata pertaining to the corpus or CMC dataset-->
</teiHeader>
<TEI>
<!-- a CMC document such as a chat log or a discussion page -->
<teiHeader>
<!-- metadata pertaining to the CMC document -->
</teiHeader>
<text>
<body>
<div>
<!-- subdivisions of the CMC document e.g. in sections or threads if applicable-->
<post>
<!-- one post -->
</post>
<!-- more posts -->
</div>
</body>
</text>
</TEI>
<!-- more documents -->
</teiCorpus>
TEI: Sequences, Sections, Threads⚓︎9.4.2 Sequences, Sections, Threads
As shown in Example 9.3.2 Attributes Specific to CMC post above, nested threads of posts may be encoded sequentially, while the indentLevel attribute of post is used to keep track of the original nesting depth. This is especially meant for CMC text obtained from a wiki code or HTML source, where it is not always entirely clear whether the indentation information actually reflects a reply action from a user.
In genres where technical reply information is available for each post, reply links can be encoded using the replyTo attribute on post elements, as shown in the second example of 9.3.2 Attributes Specific to CMC post. The network of all reply links will then also form a threaded structure, and visual indentations can be reconstructed from it and need not be explicitly encoded.
<post>...</post>
<div type="thread" n="1">
<post> ... </post>
<post> ... </post>
<div type="thread" n="2">
<!-- posts -->
</div>
</div>
</div>
<post type="comment" xml:id="cmc_post01"
who="#u7" when-iso="2015-07-29T21:44">
<p>Es hat den Anschein, ...</p>
</post>
<div type="thread" n="1">
<post type="comment" xml:id="cmc_post02"
who="#u8" when-iso="2015-07-30T19:11">
<p>Nein Nein, an den Handwerkern kann es ...</p>
</post>
<div type="thread" n="2">
<post type="comment" xml:id="cmc_post03"
who="#u8" when-iso="2015-07-30T19:26">
<p>Stahlkunstruktionen dacht ich mal, ....</p>
</post>
</div>
</div>
</div>
TEI: Multimodal CMC⚓︎9.4.3 Multimodal CMC
As explained in section 9.2 Basic Units of CMC, the elements post, u, kinesic, and incident are available to encode textual transcriptions of written posts, spoken turns, bodily activities of avatars, and onscreen activity by users that occur in CMC data; and, as discussed in section 9.3.2 Attributes Specific to CMC post, graphics or other media data within posts are encoded in a post with modality set to written. When two or more of these features occur in a CMC interaction, we can speak of multimodal CMC.
Some basic multimodality is available in many private chat systems such as WhatsApp, where spoken and written posts and media posts containing images or video clips can alternate in the sequence of posts. The following shows the suggested encoding of an extended part of the haircut chat example from above, including a spoken post, several written posts, and a post containing a graphic image (adapted from the MoCoDa2 corpus Beißwenger et al. (eds.) (visited 30 March 2022))
synch="#cmc-haircut_t004" who="#cmc-haircut_A05"
xml:id="cmc-haircut_m9"> In Düsseldorf gibt's da so Abstufungen. Da gibt's einmal Oliver
Schmidt, Oliver Schmidt's Hair Design, also dann, ist eher also, keine Ahnung, zum
Beispiel ich war da bei dem etwas Günstigeren dann. Ich weiß nicht, ob's das in Essen auch
gibt diese Abstufungen </post>
<post modality="written"
generatedBy="human" synch="#cmc-haircut_t004"
who="#cmc-haircut_A02" xml:id="cmc-haircut_m10"> Ich schau mal :) </post>
<post modality="written"
generatedBy="human" synch="#cmc-haircut_t005"
who="#cmc-haircut_A06" xml:id="cmc-haircut_m11"> Ich gehe immer nach Katernberg zu Pasha’s
haarem Hahaha also die sind echt entspannt und gut und nicht teuer </post>
<post modality="written"
generatedBy="human" synch="#tcmc-haircut_005"
who="#cmc-haircut_A06" xml:id="cmc-haircut_m12">
<figure type="image" generatedBy="human">
<desc xml:lang="en">screenshot of the google search for hairdresser "Pasha's Haare'm"
with the average google rating (4,5 of 5 stars), the address, the phone number, and
the opening hours. </desc>
</figure>
</post>
<post modality="written"
generatedBy="human" synch="#cmc-haircut_t006"
who="#cmc-haircut_A03" xml:id="cmc-haircut_m13"> Olivers hair und Oliver Schmidt gehören
zusammen </post>
<body>
<u xml:id="cmr-archi21-slrefl-es-j3-1-a191"
who="#tingrabu"
start="#cmr-archi21-slrefl-es-j3-1-ts373" end="#cmr-archi21-slrefl-es-j3-1-ts430">ok
hm for me this presentation was hm <pause dur="PT1S"/> become too fast because it's
always the same in our architecture school euh we have not time and hm <pause dur="PT1S"/> too quickly sorry [...]</u>
<kinesic xml:id="cmr-archi21-slrefl-es-j3-1-a192"
who="#romeorez"
start="#cmr-archi21-slrefl-es-j3-1-ts376" end="#cmr-archi21-slrefl-es-j3-1-ts377"
type="body" subtype="kinesics">
<desc>
<code>eat(popcorn)</code>
</desc>
</kinesic>
<!-- more bodily activities of avatars -->
<post modality="written"
generatedBy="human" xml:id="cmr-archi21-slrefl-es-j3-1-a195"
who="#tfrez2"
start="#cmr-archi21-slrefl-es-j3-1-ts380" end="#cmr-archi21-slrefl-es-j3-1-ts381"
type="chat-message">
<p>it went too quickly?</p>
</post>
</body>
</text>
Note that the spoken utterance u represents a speaker turn that was transmitted via an audio channel of the application that is continuously open during a session, whereas a spoken post represents a spoken message that has been recorded in private and been posted to the CMC server as a whole. See section 9.2 Basic Units of CMC.
TEI: Documenting CMC (and providing general metadata)⚓︎9.5 Documenting CMC (and providing general metadata)
TEI: Documenting the Source of a Corpus of CMC data⚓︎9.5.1 Documenting the Source of a Corpus of CMC data
The teiHeader of the corpus should contain metadata about the CMC platform(s), e.g. its name, information about its owner (often a company) including their address or location, the URL of the server where the CMC data were collected from, or the filename of a database dump that was used as a source. Metadata about the project responsible for collecting the data and building the corpus, if applicable, should be recorded as well.
<biblFull>
<titleStmt>
<title>Twitter Sample</title>
</titleStmt>
<publicationStmt>
<distributor>Twitter International Company</distributor>
<address>
<addrLine>1 Cumberland Place</addrLine>
<addrLine>Fenian Street</addrLine>
<addrLine>Dublin 2</addrLine>
<postCode>D02 AX07</postCode>
<country>Ireland</country>
</address>
<ptr target="https://twitter.com/"/>
<date when="2024-04-27"/>
</publicationStmt>
</biblFull>
</sourceDesc>
<biblFull>
<titleStmt>
<title>German Wikipedia Data Dump of 2019-08-01</title>
</titleStmt>
<editionStmt>
<edition>Dump file in XML (compressed)</edition>
</editionStmt>
<extent>
<measure unit="GiB" quantity="7.9"/>
</extent>
<publicationStmt>
<publisher>Wikimedia Foundation, Inc.</publisher>
<pubPlace>
<ptr target="https://dumps.wikimedia.org/"/>
</pubPlace>
<date when="2019-08-01">01 Aug 19</date>
<idno type="dump-filename">dewiki-2019-08-01-pages-meta-current</idno>
</publicationStmt>
</biblFull>
</sourceDesc>
TEI: Describing the Source of a CMC Document⚓︎9.5.2 Describing the Source of a CMC Document
A CMC document may be a chat logfile, a discussion page, or a thematical thread of posts as encoded within a TEI element. Among the metadata to be recorded in the sourceDesc of its teiHeader are, if available, its title, author or owner, its URL, the date of its creation and/or the date of its last change (i.e. the time when the last post was added to it).
<bibl>
<title type="main">Iron Man 3 in 3D (Official Trailer German) Parodie</title>
<respStmt>
<name type="user">DieAussenseiter</name>
<resp>posted video, created page</resp>
</respStmt>
<distributor>YouTube</distributor>
<ptr type="url"
target="https://www.youtube.com/watch?v=T-WU_3-0UpU"/>
<series>
<title>DieAussenseiter’s Channel</title>
<ptr target="https://www.youtube.com/watch?v=UCKn1vL4Ou4DKu0BlcK3NlDQ"/>
</series>
</bibl>
</sourceDesc>
<bibl>
<title type="main">Diskussion:FKM-Richtlinie</title>
<author>
<name type="user">OnkelSchuppig</name>, et al.</author>
<publisher>Wikimedia Foundation, Inc.</publisher>
<ptr target="https://de.wikipedia.org/wiki/Diskussion:FKM-Richtlinie"
type="page_url" targetLang="de"/>
<date type="last-change"
when="2013-09-14T17:04:48Z"/>
<idno type="wikipedia-id">7632113</idno>
<relatedItem type="articleLink">
<ref n="5138958"
target="https://de.wikipedia.org/wiki/FKM-Richtlinie" targetLang="de">FKM-Richtlinie</ref>
</relatedItem>
</bibl>
</sourceDesc>
TEI: Documenting the Sampling of CMC data⚓︎9.5.3 Documenting the Sampling of CMC data
The documentation of how the data were collected, e.g. how it was scraped or sampled from the web, or downloaded from a server, should be recorded in the samplingDecl. Like other metadata, information about sampling should be recorded at the highest level applicable. That is, if the information applies to an entire corpus, the samplingDecl should appear in the teiHeader of the corpus level; if the information is different for each document, it should appear in the teiHeader of the document level texts.
- interface: The API that was used for the download, possibly encoded as a <name type="API">;
- client: The client or other tool that was used for the download, possibly encoded as a <name type="client">;
- query: The query or command used for the download, possibly encoded with a <ptr type="query"> when it is a URI, or a code when it is a command;
- date: The date of the download.
<p>Sampled using the <name type="API">Twitter Filtered stream v2-API</name> (see <ptr type="APIdoc"
target="https://developer.twitter.com/en/docs/twitter-api/tweets/filtered-stream/api-reference/get-tweets-search-stream"/>) Filtered for the German language and the following countries: Germany, Austria,
Belgium, Switzerland, Denmark, and Luxembourg. Downloaded on <date when="2022-12-12">Mon 12 Dec 22</date> using the command
<code>requests.get("https://api.twitter.com/2/tweets/search/stream",
headers=headers, params=params, stream=True,)</code> in the python script <name type="script">collectFilteredTwitterStream.py</name>. </p>
</samplingDecl>
<p>Downloaded from the news.individual.de server on 2016-01-15 using nntp client in
Python</p>
</samplingDecl>
TEI: Participants⚓︎9.5.4 Participants
A listPerson may be used to maintain an inventory of users and bots taking part in a CMC interaction, along with information about them. As with other such contextual information, it may be kept in the teiHeader (where it would occur in a particDesc within a profileDesc) or in a separate document completely. In either case, an encoded post may then be linked to its author by use of the who attribute.
<!-- In the <teiHeader>: --><profileDesc>
<particDesc>
<listPerson>
<person role="user" sex="male"
xml:id="cmc_user_01">
<persName type="userName">M</persName>
<note type="link">/wiki/User:M</note>
<affiliation>
<email>mike@mydomain.com</email>
<country>CH</country>
</affiliation>
</person>
<!-- … more persons … -->
<person role="user" sex="female"
xml:id="cmc_user_06">
<persName type="userName">P</persName>
<note type="link">/wiki/User:P</note>
<affiliation>
<email>pat@super.net</email>
<country>ES</country>
</affiliation>
</person>
<person role="user" xml:id="cmc_user_07">
<persName type="userName">PKP</persName>
<note type="link">/wiki/User:Pi</note>
</person>
</listPerson>
</particDesc>
</profileDesc>
<!-- In the <body>: -->
<div type="wiki_discussion_page" n="073">
<!-- 4 other <post>s -->
<post modality="written"
xml:id="cmc_post04" indentLevel="1"
replyTo="#cmc_post_073.004" who="#cmc_user_06">
<p>Those haven't happened. If they do, we can revisit the concern.</p>
<signed generatedBy="template"
rend="noLineBreak">
<ref target="/wiki/User:P">P</ref>
<date>01:35, 8 April 2014 (UTC)</date>
</signed>
</post>
</div>
<!-- In the <body>: --><div type="wiki_discussion_page" n="073">
<!-- 4 other <post>s -->
<post modality="written"
xml:id="cmc_post05" indentLevel="1"
replyTo="#cmc_post_073.004" who="./userList.xml#cmc_user_06">
<p>Those haven't happened. If they do, we can revisit the concern.</p>
<signed generatedBy="template"
rend="noLineBreak">
<ref target="/wiki/User:P">P</ref>
<date>01:35, 8 April 2014 (UTC)</date>
</signed>
</post>
</div>
uL: could be used to map the value uL:06 to file:/userList.xml#cmc_user_06. See 17.2.3 Using Abbreviated Pointers for more information on establishing prefix definitions.This indirection—using a listPerson, particularly one in a separate file, to store information about the users involved in a CMC interaction—is particularly useful when there is both a need to keep such information locally, and to remove it (e.g., to ‘anonymize’ the data) when the data are published or shared with other researchers.
TEI: Timeline⚓︎9.5.5 Timeline
who="#f2213001.A06" xml:id="cmc_post06">
<time generatedBy="system">21:52</time>
das ist auf jedenfall krankheit
</post>
xml:id="cmc_post07" indentLevel="1" who="#u006" synch="#t006">
<p>Those haven't happened. If they do, we can revisit the concern.</p>
<signed generatedBy="template">
<ref target="/wiki/User:P">P</ref>
<date when="2014-04-08T01:35:00Z">01:35, 8 April 2014 (UTC)</date>
</signed>
</post>
when="2014-04-08T01:35:00Z" who="#u006">
<p>Those haven't happened. If they do, we can revisit the concern.</p>
<signed generatedBy="template">
<ref target="/wiki/User:P">P</ref>
</signed>
</post>
<particDesc>
<listPerson>
<person role="user" xml:id="u001">
<persName type="userName">M</persName>
<note type="link">/wiki/User:M</note>
</person>
<!-- more persons -->
<person role="user" xml:id="u006">
<persName type="userName">P</persName>
<note type="link">/wiki/User:P</note>
</person>
<person role="user" xml:id="u007">
<persName type="userName">PKP</persName>
<note type="link">/wiki/User:Pi</note>
</person>
</listPerson>
</particDesc>
<textDesc>
<channel/>
<constitution/>
<derivation/>
<domain/>
<factuality/>
<interaction>
<timeline>
<when xml:id="t001"
absolute="2011-03-23T19:56:00"/>
<when xml:id="t002"
absolute="2011-06-14T21:22:00"/>
<when xml:id="t003"
absolute="2011-06-14T23:28:00"/>
<when xml:id="t004"
absolute="2011-07-02T07:20:00"/>
<when xml:id="t005"
absolute="2011-07-21T01:00:00"/>
<when xml:id="t006"
absolute="2014-04-08T01:35:00"/>
</timeline>
</interaction>
<preparedness/>
<purpose/>
</textDesc>
</profileDesc>
xml:id="cmc_post08" indentLevel="1" who="#u006" synch="#t006">
<p>Those haven't happened. If they do, we can revisit the concern. </p>
<signed generatedBy="template"> [_DELETED-SIGNATURE_]
<date synch="#t007">[_DELETED-TIMESTAMP_]</date>
</signed>
</post>
TEI: Recommendations for Encoding CMC Microstructure⚓︎9.6 Recommendations for Encoding CMC Microstructure
TEI: Emojis and Emoticons⚓︎9.6.1 Emojis and Emoticons
Emojis are iconic or symbolic, invariant graphic units which the users of social media applications such as WhatsApp, Instagram, and X (Twitter) can select from a menu or ‘emoji keyboard’ and embed into their written posts. Examples are 😁, 😷, 🌈, 😱, and 🙈. An emoji is encoded by one or more Unicode characters which are intended to be mapped directly to a pictorial symbol.
Emoticons predate emojis and are created as combinations of ASCII punctuation and
other characters using the keyboard. Examples are :-), ;-), :-(, :-x, \O/, and Oo. They first occurred on a computer bulletin board system at Carnegie Mellon University
(Fahlman, 2021) and then became frequent in chat communications during the mid-1980s. An emoticon
typically consists of several Unicode characters (from the ASCII subset) in a row,
each of which has an intended use other than as part of an emoticon.
Both emoticons and emojis may be simply transcribed as a sequence of characters. As
with any other characters, they may be entered as numeric character entities if this
is more convenient. (E.g., ❤ might be transcribed as ❤ in any XML document, including a TEI document; see Entry of Characters.)
When the text of a post is being tokenized, e.g. for linguistic analysis, it may be useful to encode the emoticon or emoji as a separate token. In such cases elements such as w or c may be used for tokenization, and the pos attribute may be used to indicate that the encoded string is an emoji or an emoticon. (See 18.1 Linguistic Segment Categories.)
<w pos="ADV">da</w>
<w pos="VAFIN">bin</w>
<w pos="PPER">ich</w>
<w pos="PTKNEG">nicht</w>
<w pos="ADV">so</w>
<w pos="ADJD">empfindlich</w>
<w pos="EMOASC">;)</w>
</post>
generatedBy="human" synch="#lscLB.t004" who="#lscLB.A03"
xml:id="cmc_post21">
<w pos="ADV">Klar</w>
<w pos="EMOIMG">😁</w>
</post>
The values of pos in the above examples are from the STTS_IBK Tagset for German (see Beißwenger et al. (2015-09-13)), which includes tags for CMC-specific elements such as EMOASC for an ASCII-based emoticon and EMOIMG for an icon-based emoji.
generatedBy="template">😱</c>
</post>
Sometimes, e.g. when the source of the TEI document was a web page in HTML, the emojis may occur only as an icon graphic in the source. In such a case, they may be encoded using figure. The corresponding Unicode character can then be recorded in the desc element by the encoder if desired.
generatedBy="human" synch="#lscLB.t004" who="#lscLB.A03"
xml:id="cmc_post22"> ... ich überlege noch <figure type="emoji"
generatedBy="template">
<graphic url="fig1.png"/>
<desc type="gloss" xml:lang="en">see no evil monkey</desc>
<desc type="unicode">U+1F648</desc>
</figure>
</post>
TEI: Posts with Graphics⚓︎9.6.2 Posts with Graphics
A post in a CMC interaction may contain a graphic in addition to some text or even contain only a graphic (without any text). As explained in 9.3.2 Attributes Specific to CMC post, the modality of such a post should be considered as written. To encode the graphic information, the figure element may be used at the appropriate place.
generatedBy="human" synch="#t005" who="#A06"
xml:id="cmc_post23">
<figure type="image" generatedBy="human">
<desc>screenshot of the google search for hairdresser "Pasha's Haare'm" with the
average google rating (4,5 of 5 stars), the address, the phone number, and the
opening hours. </desc>
</figure>
</post>
generatedBy="human" synch="#tweetsbcrn18.t006"
xml:id="cmc_post_1043823300479258624" who="#u1" xml:lang="de">
<time generatedBy="system"> 16:24 </time> Bro Tri-Engel...so hab ich mir das
vorgestellt!!! @AndreLo79 #bcrn18 #wikidach @Heiko komm' mal Twitter! #Engel <figure type="image" generatedBy="human">
<graphic url="https://pbs.twimg.com/media/DnxnwN9XsAEHXw2.jpg:large"/>
</figure>
</post>
TEI: Circulation⚓︎9.6.3 Circulation
The following recommendations on how to encode features of the circulation of posts, such as IDs, re-posts (retweets), hashtags, and mentions use X (Twitter) posts (tweets) as an example; this phenomenon is not in any way unique to X (Twitter), however.
In the following example, the type of post (in this case, a tweet) is recorded using the type attribute of post. If it were useful to record a particular sub-categorization of tweet, the subtype attribute could also be used. Furthermore, the original unique identifer of the tweet as supplied by X (Twitter) is recorded as part of the value of the xml:id attribute of the post.
Also in the following example a retweet and its corresponding retweeted tweet are encoded as two separate posts each with its own set of attributes. The post representing the retweet itself does not contain or duplicate the content of the retweeted tweet. Instead it refers to the ID of the retweeted tweet via a ptr in the post content. All original content of the retweet goes in the content of the post element as well. In addition, the hashtags found in the body of the source tweets have been encoded using ref elements (with a type of hashtag), as they are links like any other hyperlink.
generatedBy="human" type="tweet" who="#u1"
xml:id="cmc_post_1043796550101716993" synch="#tweetsbcrn18.t004" xml:lang="de">
<ptr type="retweet"
target="#cmc_post_1043796093786566656"/> Ich mich auch? <ref type="hashtag"
target="https://twitter.com/hashtag/dynamicduo?src=hash">#dynamicduo</ref>
<ref type="hashtag"
target="https://twitter.com/hashtag/wirk%C3%BCmmernunsauchumIhrenEmpfang?src=hash">#wirkümmernunsauchumIhrenEmpfang</ref>
<ref type="hashtag"
target="https://twitter.com/hashtag/bcrn18?src=hash">#bcrn18</ref>
<ref type="hashtag"
target="https://twitter.com/hashtag/wikidach?src=hash">#wikidach</ref>
</post>
<post modality="written"
generatedBy="human" type="tweet" who="#u2"
synch="#tweetsbcrn18.t003" xml:lang="de"
xml:id="cmc_post_1043796093786566656">
<time generatedBy="system"> 14:35 </time> Immer wieder gerne. Kann ich mich schon für
nächstes Jahr als Empfangs- <ref type="hashtag"
target="https://twitter.com/hashtag/Engel?src=hash">#Engel</ref> für das nächste
BarCamp bewerben <w pos="EMO">🤪</w>
<ref type="hashtag"
target="https://twitter.com/hashtag/bcrn18?src=hash">#bcrn18</ref>
<trailer>
<fs>
<f name="favoritecount">
<numeric value="4"/>
</f>
</fs>
</trailer>
</post>
Note that in the above example ‘CoMeRe’ style (cf. Thierry et al. (2014)) encoding is used to represent the number of favorites. It would also be reasonable to use a TEI measure element instead of the fs.
TEI: Linguistic Annotation⚓︎9.6.4 Linguistic Annotation
For encoding linguistic analyses of CMC text, we may use the dedicated elements and attributes from the analysis module, which is described in 17 Linking, Segmentation, and Alignment. For example, the tokenization (segmentation into word-like units) of a CMC text should be encoded using the w element.
rend="color:black" synch="#t010.a" who="#A03.a"
xml:id="cmc_post_m16.a">
<time>00:22</time>
<w>Bin</w>
<w>soooooo</w>
<w>im</w>
<w>stress</w>
<w>gewesen</w>
<w>ich</w>
<w>Armer</w>
<w>lol</w>
</post>
In many CMC genres, especially in private chat, informal writing abounds including irregular spellings imitating spoken language, omitted word boundaries, and spurious boundaries leading to tokens separated in parts. For encoding these writing phenomena typical of CMC, the TEI attributes norm and join may be used.
rend="color:black" synch="#t010.b" who="#A03.b"
xml:id="cmc_post_m16.b">
<time> 00:22 </time>
<w>Bin</w>
<w norm="so">soooooo</w>
<w>im</w>
<w norm="Stress">stress</w>
<w>gewesen</w>
<w>ich</w>
<w>Armer</w>
<w>lol</w>
</post>
<choice>
<orig>
<w pos="VAPPER" lemma="">hastes</w>
</orig>
<reg>
<w pos="VAFIN" lemma="haben">hast</w>
<w pos="PPER" lemma="du">du</w>
<w pos="PPER" lemma="es">es</w>
</reg>
</choice>
</post>
rend="color:black" synch="#t010.c" who="#A03.c"
xml:id="cmc_post_m16.c">
<time> 00:22 </time>
<w lemma="sein" pos="VAFIN" xml:id="m16.t9">Bin</w>
<w lemma="so" norm="so" pos="PTKIFG"
xml:id="m16.t10">soooooo</w>
<w lemma="in" pos="APPRART"
xml:id="m16.t11">im</w>
<w lemma="Stress" norm="Stress" pos="NN"
xml:id="m16.t12">stress</w>
<w lemma="sein" pos="VAPP" xml:id="m16.t13">gewesen</w>
<w lemma="ich" pos="PPER" xml:id="m16.t14">ich</w>
<w lemma="Armer" pos="NN" xml:id="m16.t15">Armer</w>
<w lemma="lol" pos="AKW" xml:id="m16.t16">lol</w>
</post>
TEI: Named Entities and Anonymization⚓︎9.6.5 Named Entities and Anonymization
generatedBy="system" rend="color:black" synch="#f2213001.t007"
type="standard" who="#f2213001.A04"
xml:id="f2213001.m27.eg35">
<name ref="#f2213001.A04" type="NICK">
<w lemma="Konstanze" pos="NE"
xml:id="f2213001.m27.t1">Konstanze</w>
</name>
<w lemma="versuchen" pos="VVPP">versucht</w>
<name ref="#f2213001.A03" type="NICK">
<w lemma="Nasenloch" pos="NN">nasenloch</w>
</name>
<w lemma="die" pos="ART">den</w>
<w lemma="Wunsch" pos="NN">wunsch</w>
<w lemma="zu" pos="PTKZU">zu</w>
<w lemma="erfüllen" pos="VVINF">erfüllen</w>
<!-- ... -->
</post>
generatedBy="system" rend="color:black"
synch="#f2213001a.t007" type="standard" who="#f2213001a.A04"
xml:id="f2213001a.m27.eg35">
<name ref="#f2213001a.A04" type="NICK">
<w pos="NE" xml:id="f2213001a.m27.t1">
<gap reason="anonymization" unit="token"
quantity="1"/>
<supplied reason="anonymization">[_FEMALE-PARTICIPANT-A04_]</supplied>
</w>
</name>
<w lemma="versuchen" pos="VVPP">versucht</w>
<name ref="#f2213001a.A03" type="NICK">
<w pos="NN">
<gap reason="anonymization" unit="token"
quantity="1"/>
<supplied reason="anonymization">[_PARTICIPANT-A04_]</supplied>
</w>
</name>
<w lemma="die" pos="ART">den</w>
<w lemma="Wunsch" pos="NN">wunsch</w>
<w lemma="zu" pos="PTKZU">zu</w>
<w lemma="erfüllen" pos="VVINF">erfüllen</w>
<!-- ... -->
</post>
In the preceding example, pairs of a gap and a supplied element encode the fact that some substring has been removed and replaced with another string for anonymization purposes. Note that in this example, the name and the w elements and their attributes also provide some categorical information about what has been removed. Using gap and supplied to record the anonymization is especially recommendable when the original name or referencing string has been ‘pseudonymized’, i.e. replaced by a different referencing string of the same ontological category (such as replacing the female name Konstanze by the female name Kornelia.). In that case, the markup would be the only place where it can be seen that a pseudonymization has been carried out, as in the following version of the example.
generatedBy="system" rend="color:black"
synch="#f2213001p.t007" type="standard" who="#f2213001p.A04"
xml:id="f2213001p.m27.eg35">
<name ref="#f2213001p.A04" type="NICK">
<w pos="NE" xml:id="f2213001p.m27.t1">
<gap reason="pseudonymization"
unit="token" quantity="1"/>
<supplied reason="pseudonymization">Kornelia</supplied>
</w>
</name>
<w lemma="versuchen" pos="VVPP">versucht</w>
<!-- the rest of the post -->
</post>
TEI: The TEI CMC Module⚓︎9.7 The TEI CMC Module
The module described in this chapter makes available the following components:
- Modulo cmc: Computer-mediated communication
-
- Elementi definiti: post
- Macro definite: macro.specialPara.cmc
The selection and combination of modules to form a TEI schema is described in 1.2 Defining a TEI Schema.